Transformers State-of-the-art Natural Language Processing for Jax, Pytorch and TensorFlow
RoBERTa Overview The RoBERTa model was proposed in
RoBERTa: A Robustly Optimized BERT Pretraining Approach
by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google’s BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with much larger mini-batches and learning rates.
The abstract from the paper is the following:
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.
Coleridge Initiative - Show US the Data, Discover how data is used for the public good
In this competition, you'll use natural language processing (NLP) to automate the discovery of how scientific data are referenced in publications. Utilizing the full text of scientific publications from numerous research areas gathered from CHORUS publisher members and other sources, you'll identify data sets that the publications' authors used in their work.
Harvard Data Science Review • Issue 3.2, Spring 2021 Enhancing and Accelerating Social Science Via Automation: Challenges and Opportunities
Tal Yarkoni, Dean Eckles, James A. J. Heathers, Margaret C. Levenstein, Paul E. Smaldino, Julia Lane Published on: Apr 30, 2021 DOI: 10.1162/99608f92.df2262f5
6月11日(金)
Coleridge Initiative:
1,483 teams
12 days to go
The objective of the competition is to identify the mention of datasets within scientific publications. Your predictions will be short excerpts from the publications that appear to note a dataset.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova, Google AI Language arXiv:1810.04805v2 [cs.CL] 24 May 2019
Abstract We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
トランスフォーマーからの双方向エンコーダー表現を表すBERTと呼ばれる新しい言語表現モデルを紹介します。 最近の言語表現モデル(Peters et al。、2018a; Radford et al。、2018)とは異なり、BERTは、すべてのレイヤーで左右両方のコンテキストを共同で調整することにより、ラベルのないテキストから深い双方向表現を事前トレーニングするように設計されています。 その結果、事前にトレーニングされたBERTモデルを1つの追加出力レイヤーで微調整して、質問応答や言語推論などの幅広いタスク用の最先端のモデルを作成できます。タスク固有のアーキテクチャを大幅に変更する必要はありません。by Googlr翻訳
A.3 Fine-tuning Procedure For fine-tuning, most model hyperparameters are the same as in pre-training, with the exception of the batch size, learning rate, and number of training epochs. The dropout probability was always kept at 0.1. The optimal hyperparameter values are task-specific, but we found the following range of possible values to work well across all tasks: • Batch size: 16, 32 • Learning rate (Adam): 5e-5, 3e-5, 2e-5 • Number of epochs: 2, 3, 4
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc") >>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc")
Extractive Question Answering:
>>> tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad") >>> model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
Language Modeling:
Language modeling is the task of fitting a model to a corpus, which can be domain specific. All popular transformer-based models are trained using a variant of language modeling, e.g. BERT with masked language modeling, GPT-2 with causal language modeling.
Language modeling can be useful outside of pretraining as well, for example to shift the model distribution to be domain-specific: using a language model trained over a very large corpus, and then fine-tuning it to a news dataset or on scientific papers e.g. LysandreJik/arxiv-nlp.
Masked Language Modeling:
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-cased") >>> model = AutoModelWithLMHead.from_pretrained("distilbert-base-cased")
Causal Language Modeling:
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2") >>> model = AutoModelWithLMHead.from_pretrained("gpt2")
Text Generation:
>>> model = AutoModelWithLMHead.from_pretrained("xlnet-base-cased") >>> tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
Named Entity Recognition:
>>> model = AutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english") >>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
Summarization:
Summarization is the task of summarizing a document or an article into a shorter text. If you would like to fine-tune a model on a summarization task, you may leverage the run_summarization.py script.
>>> model = AutoModelWithLMHead.from_pretrained("t5-base") >>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
Translation:
Translation is the task of translating a text from one language to another. If you would like to fine-tune a model on a translation task, you may leverage the run_translation.py script.
>>> model = AutoModelWithLMHead.from_pretrained("t5-base") >>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
>>> inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="pt") >>> outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True)
>>> print(tokenizer.decode(outputs[0])) Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer, Facebook AI arXiv:1910.13461v1 [cs.CL] 29 Oct 2019
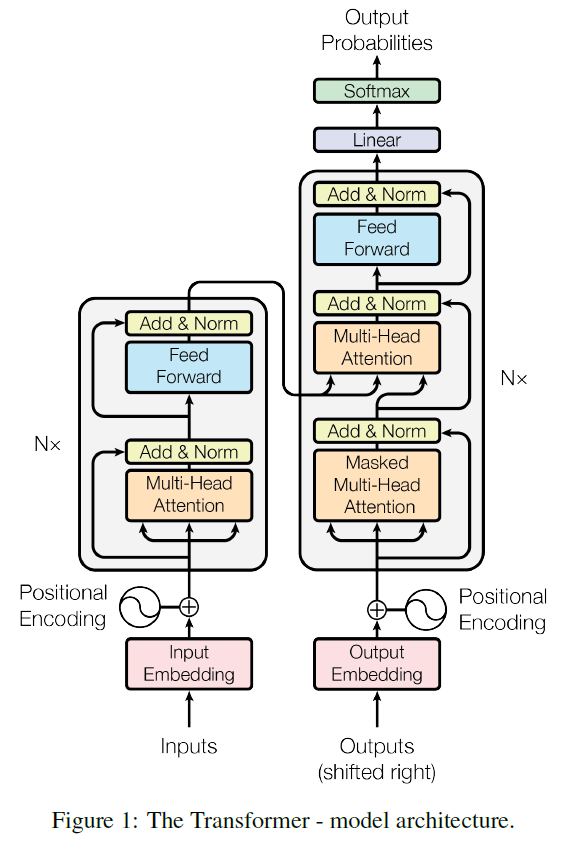
In this paper, we present BART, which pre-trains a model combining Bidirectional and Auto-Regressive Transformers. BART is a denoising autoencoder built with a sequence-to-sequence model that is applicable to a very wide range of end tasks. Pretraining has two stages (1) text is corrupted with an arbitrary noising function, and (2) a sequence-to-sequence model is learned to reconstruct the original text. BART uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pretraining schemes (see Figure 1).
Google Smartphone Decimeter Challenge Improve high precision GNSS positioning and navigation accuracy on smartphones
Global Navigation Satellite System (GNSS) provides raw signals, which the GPS chipset uses to compute a position. Current mobile phones only offer 3-5 meters of positioning accuracy. While useful in many cases, it can create a “jumpy” experience. For many use cases the results are not fine nor stable enough to be reliable.
In this competition, you'll use data collected from the host team’s own Android phones to compute location down to decimeter or even centimeter resolution, if possible. You'll have access to precise ground truth, raw GPS measurements, and assistance data from nearby GPS stations, in order to train and test your submissions.
Fast Kalman filters in Python leveraging single-instruction multiple-data vectorization. That is, running n similar Kalman filters on n independent series of observations. Not to be confused with SIMDprocessor instructions.
カルマンフィルターは、 離散的な誤差のある観測から、時々刻々と時間変化する量(例えばある物体の位置と速度)を推定するために用いられる。レーダーやコンピュータビジョンなど、工学分野で広く用いられる。例えば、カーナビゲーションでは、機器内蔵の加速度計や人工衛星からの誤差のある情報を統合して、時々刻々変化する自動車の位置を推定するのに応用されている。カルマンフィルターは、目標物の時間変化を支配する法則を活用して、目標物の位置を現在(フィルター)、未来(予測)、過去(内挿あるいは平滑化)に推定することができる。by Wikipedia
Berkeley SETI Research Center:942 teams, a month to go
Image Size vs Scoreというタイトルで情報のやりとりが行われている。画像解像度が高いほどスコアは高い傾向にある。コードコンペではないので、使える計算資源による差が現れやすい。What's your best single model?ここでも画像サイズが話題になり、大きな画像で良いスコアだが、Kaggle kernelでは動かないという話。最後には、アンサンブルの話。
MLB Player Digital Engagement Forecasting Predict fan engagement with baseball player digital content
engagementが何を意味しているのかが、わからない。
In this competition, you’ll predict how fans engage with MLB players’ digital content on a daily basis for a future date range. You’ll have access to player performance data, social media data, and team factors like market size. Successful models will provide new insights into what signals most strongly correlate with and influence engagement.
Google Smartphone Decimeter Challenge:474 teams, 2 months to go
Our team is currently using only post processing to improve the accuracy. We have found that the order of post processing changes the accuracy significantly, so we share the results.
ポストプロセスに関する手順と効果に関するDiscussionが行われている。
6月18日(金)
Berkeley SETI Research Center:1,001 teams, a month to go
There are just a few of us data scientists at Kaggle launching about 50 competitions a year with many different data types over a very wide range of domains. Worrying about leakage and other failure points keeps us up at night. We absolutely value our community's time and effort and know how important it is to have fun and challenging competitions.
As this competition is brought to you in collaboration with the launch of Vertex AI, we're providing GCP coupons for users to try out some of the great, powerful new resources made available through Vertex AI. This includes JupyterLab Notebooks, Explainable AI, hyperparameter tuning through Vizier, and countless other AI training and deployment tools.
Vertex AI brings AutoML and AI Platform together into a unified API, client library, and user interface. AutoML allows you to train models on image, tabular, text, and video datasets without writing code, while training in AI Platform lets you run custom training code. With Vertex AI, both AutoML training and custom training are available options. Whichever option you choose for training, you can save models, deploy models and request predictions with Vertex AI.
JupyterLab is a next-generation web-based user interface for Project Jupyter.
Notebooks enables you to create and manage virtual machine (VM) instances that are pre-packaged with JupyterLab.
Notebooks instances have a pre-installed suite of deep learning packages, including support for the TensorFlow and PyTorch frameworks. You can configure either CPU-only or GPU-enabled instances, to best suit your needs.
Your Notebooks instances are protected by Google Cloud authentication and authorization, and are available using a Notebooks instance URL. Notebooks instances also integrate with GitHub so that you can easily sync your notebook with a GitHub repository.
Notebooks saves you the difficulty of creating and configuring a Deep Learning virtual machine by providing verified, optimized, and tested images for your chosen framework.
Introduction to Vertex Explainable AI for Vertex AI
Images in the test set may contain more than one object.
For each object in a given test image, you must predict a class ID of "opacity", a confidence score, and bounding box in format xmin ymin xmax ymax.
If you predict that there are NO objects in a given image, you should predict none 1.0 0 0 1 1, where none is the class ID for "No finding", 1.0 is the confidence, and 0 0 1 1 is a one-pixel bounding box.
<雑談>AI, Machin Learning, Deep Learning, Data Science, Engineer or Scientist or Programmer, Kaggler:これらの単語からイメージされる領域で、自分が目指す方向を表現するのに適しているのは何か。AIは、漠然としていてつかみどころがない。Data Scienceは、自分の中では前処理のイメージが強い。Wikipediaで調べてみよう。
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data,[1][2] and apply knowledge and actionable insights from data across a broad range of application domains. Data science is related to data mining, machine learning and big data.
Data Scienceは、Machin Learning、Deep Learningだけでなく、あらゆる科学技術分野に対して、横断的に関連しているものと捉えることができるもののようである。
Data mining is a process of extracting and discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems.[1] Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal to extract information (with intelligent methods) from a data set and transform the information into a comprehensible structure for further use.
勝手な解釈かもしれないが、data mining + big data = data scienceということにして、自分の現在および近未来の専門領域は、仮に、Data Scientistとしておこう。
AutoDS: Towards Human-Centered Automation of Data Science
Dakuo Wang et al., arXiv:2101.05273v1 [cs.HC] 13 Jan 2021
Abstract
Data science (DS) projects often follow a lifecycle that consists of laborious tasks for data scientists and domain experts (e.g., data exploration, model training, etc.). Only till recently, machine learning(ML) researchers have developed promising automation techniques to aid data workers in these tasks. This paper introduces AutoDS, an automated machine learning (AutoML) system that aims to leverage the latest ML automation techniques to support data science projects. Data workers only need to upload their dataset, then the system can automatically suggest ML configurations, preprocess data, select algorithm, and train the model. These suggestions are presented to the user via a web-based graphical user interface and a notebook-based programming user interface. We studied AutoDS with 30 professional data scientists, where one group used AutoDS, and the other did not, to complete a data science project. As expected, AutoDS improves productivity; Yet surprisingly, we find that the models produced by the AutoDS group have higher quality and less errors, but lower human confidence scores. We reflect on the findings by presenting design implications for incorporating automation techniques into human work in the data science lifecycle.
5.2. ImageNet Results for EfficientNet We train our EfficientNet models on ImageNet using similar settings as (Tan et al., 2019): RMSProp optimizer with decay 0.9 and momentum 0.9; batch norm momentum 0.99; weight decay 1e-5; initial learning rate 0.256 that decays by 0.97 every 2.4 epochs. We also use swish activation (Ramachandran et al., 2018; Elfwing et al., 2018), fixed AutoAugment policy (Cubuk et al., 2019), and stochastic depth (Huang et al., 2016) with drop connect ratio 0.3. As commonly known that bigger models need more regularization, we linearly increase dropout (Srivastava et al., 2014) ratio from 0.2 for EfficientNet-B0 to 0.5 for EfficientNet-B7.
AutoAugment: Learning Augmentation Strategies from Data
RandAugment: Practical automated data augmentation with a reduced search space
4.stochastic depth (Huang et al., 2016) with drop connect ratio 0.3
Stochastic depth aims to shrink the depth of a network during training, while keeping it unchanged during testing. We can achieve this goal by randomly dropping entire ResBlocks during training and bypassing their transformations through skip connections.
5.linearly increase dropout (Srivastava et al., 2014) ratio from 0.2 for EfficientNet-B0 to 0.5 for EfficientNet-B7
May13/2021: Initial code release for EfficientNetV2 models: accepted to ICML'21.
1. About EfficientNetV2 Models
EfficientNetV2 are a family of image classification models, which achieve better parameter efficiency and faster training speed than prior arts.
Built upon EfficientNetV1, our EfficientNetV2 models use neural architecture search (NAS) to jointly optimize model size and training speed, and are scaled up in a way for faster training and inference speed.
6月7日(月)
Society for Imaging Informatics in Medicine (SIIM):386 teams, 2 months to go
Abstract In this paper, we address the problem of image captioning specifically for molecular translation where the result would be a predicted chemical notation in InChI format for a given molecular structure. Current approaches mainly follow rule-based or CNN+RNN based methodology. However, they seem to underperform on noisy images and images with small number of distinguishable features. To overcome this, we propose an end-to-end transformer model. When compared to attention-based techniques, our proposed model outperforms on molecular datasets.
分子構造は画像として与えられる。その画質は、新しい教科書に掲載されているような鮮明な画像ではなく、コピーを繰り返して不鮮明になった画像である。O, N, P, Sなどの元素記号は不鮮明であり、1重結合と2重結合が見分けにくいものがあり、立体構造を表す結合なども不鮮明なものがある。斑点状のノイズがのっている。
Towards a Universal SMILES representation - A standard method to generate canonical SMILES based on the InChI,
Noel M O’Boyle, Journal of Cheminformatics 2012, 4:22
Figure 1 An overview of the steps involved in generating Universal and Inchified SMILES. The normalisation step just applies to Inchified SMILES. To simplify the diagram a Standard InChI is shown, but in practice a non-standard InChI (options FixedH and RecMet) is used for Universal SMILES.
Towards a Universal SMILES representation - A standard method to generate canonical SMILES based on the InChI, Noel M O’Boyle, Journal of Cheminformatics 2012, 4:22
韓国のコンペで使われたSMILESは、2012年の時点では、最もポピュラーな1行表記方法”The SMILES format is the most popular line notation in use today."とのことであるが、課題は、立体構造の表現が困難であることの他に、標準化されていないことだということで、InChIをベースに標準化を提案しているのがこの論文の内容となっている。SMILESの標準化が進まなかった原因として、提案された方法が立体構造に対応していない、開発品の専売化、フリーソフトは互いに互換性が無く出版もされなかったことなどがあげられている。
1999年にNIST(National Institute of Standards and Technology)において、分子の新しい1行表記方法の開発がすすめられ、InChIが国際標準として提案されたようである。
この論文では、このInChIからの標準的なラベルを用いて、標準的なSMILESを生成するという方法をとっている。オープンソースの様々なケモインフォマティクスライブラリー(Open Babel, Chemistry Development Kit, RDKit, Chemkit, Indigoなど)に含まれるコードを用いることができるようである。
The following commands show how to use the obabel command-line program to generate Universal and Inchified SMILES strings for a structure stored in a Mol file: C:\>obabel figure1.mol -osmi –xU c1cc(/C=C/F)cc(c1)[N+](=O)[O-] C:\>obabel figure1.mol -osmi –xI c1cc(/C=C/F)cc(c1)N(=O)=O
昨年の9月に、たくさんのコンペに参加した中に、Halite by Two Sigma, Collect the most halite during your match in spaceというのがあった。Reinforcement Learningを試すコンペのようなので、ここでReinforcement Learningを学ぼうと思った。しかし、同時期にいくつかのコンペにも参加していたので、各コンペに避ける時間があまりにも少なく、結局、RLの学習もスコアも中途半端で終わった。このコンペのことを思い出してそのサイトに行って、トップチーム(個人)の解説をざっと読んで驚いた。その方は、なんと、Reinforcement Learningを開発したDeep Mindにおられて熟知されていたようである。当然のことながらプログラミングレベルもはかり知れないものだろうと思う。RLがトップを狙うには不十分ということで、従来型のプログラミングで勝負したとのことである。なんと11,000行、とのこと。Reinforcement Learning自体がだめということではなく、学習時間が足りないということのようである。とてもまねできないなと思ったのは、対戦状況を観察して相手の戦術を読み取ってそれを凌駕する戦術を考えてプログラミングしたことである。
DEEP REINFORCEMENT LEARNING Yuxi Li (yuxili@gmail.com), arXiv:1810.06339v1 [cs.LG] 15 Oct 2018
ABSTRACT We discuss deep reinforcement learning in an overview style. We draw a big picture, filled with details. We discuss six core elements, six important mechanisms, and twelve applications, focusing on contemporary work, and in historical contexts. We start with background of artificial intelligence, machine learning, deep learning, and reinforcement learning (RL), with resources. Next we discuss RL core elements, including value function, policy, reward, model, exploration vs. exploitation, and representation. Then we discuss important mechanisms for RL, including attention and memory, unsupervised learning, hierarchical RL, multiagent RL, relational RL, and learning to learn. After that, we discuss RL applications, including games, robotics, natural language processing (NLP), computer vision, finance, business management, healthcare, education, energy, transportation, computer systems, and, science, engineering, and art. Finally we summarize briefly, discuss challenges and opportunities, and close with an epilogue.
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems Sergey Levine, Aviral Kumar, George Tucker, Justin Fu arXiv:2005.01643v3 [cs.LG] 1 Nov 2020
Abstract In this tutorial article, we aim to provide the reader with the conceptual tools needed to get started on research on offline reinforcement learning algorithms: reinforcement learning algorithms that utilize previously collected data, without additional online data collection. Offline reinforcement learning algorithms hold tremendous promise for making it possible to turn large datasets into powerful decision making engines. Effective offline reinforcement learning methods would be able to extract policies with the maximum possible utility out of the available data, thereby allowing automation of a wide range of decision-making domains, from healthcare and education to robotics. However, the limitations of current algorithms make this difficult. We will aim to provide the reader with an understanding of these challenges, particularly in the context of modern deep reinforcement learning methods, and describe some potential solutions that have been explored in recent work to mitigate these challenges, along with recent applications, and a discussion of perspectives on open problems in the field.
World Models David Ha and Jurgen Schmidhuber, arXiv:1803.10122v4 [cs.LG] 9 May 2018
Abstract We explore building generative neural network models of popular reinforcement learning environments. Our world model can be trained quickly in an unsupervised manner to learn a compressed spatial and temporal representation of the environment. By using features extracted from the world model as inputs to an agent, we can train a very compact and simple policy that can solve the required task. We can even train our agent entirely inside of its own hallucinated dream generated by its world model, and transfer this policy back into the actual environment.
Humans develop a mental model of the world based on what they are able to perceive with their limited senses. The decisions and actions we make are based on this internal model. Jay Wright Forrester, the father of system dynamics, described a mental model as: The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system. (Forrester, 1971)
To handle the vast amount of information that flows through our daily lives, our brain learns an abstract representation of both spatial and temporal aspects of this information. We are able to observe a scene and remember an abstract description thereof. Evidence also suggests that what we perceive at any given moment is governed by our brain’s prediction of the future based on our internal model.
Leslie Pack Kaelbling, Michael L. Littman, and Andrew W. Moore,
Journal of Artificial Intelligence Research 4 (1996) 237-285
Abstract This paper surveys the field of reinforcement learning from a computer-science per- spective. It is written to be accessible to researchers familiar with machine learning. Both the historical basis of the field and a broad selection of current work are summarized. Reinforcement learning is the problem faced by an agent that learns behavior through trial-and-error interactions with a dynamic environment. The work described here has a resemblance to work in psychology, but differs considerably in the details and in the use of the word \reinforcement." The paper discusses central issues of reinforcement learning, including trading off exploration and exploitation, establishing the foundations of the field via Markov decision theory, learning from delayed reinforcement, constructing empirical models to accelerate learning, making use of generalization and hierarchy, and coping with hidden state. It concludes with a survey of some implemented systems and an assessment of the practical utility of current methods for reinforcement learning.
Deep Reinforcement Learning for Autonomous Driving: A Survey B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A. Al Sallab, Senthil Yogamani, and Patrick Pérez, arXiv:2002.00444v2 [cs.LG] 23 Jan 2021
Abstract—With the development of deep representation learning, the domain of reinforcement learning (RL) has become a powerful learning framework now capable of learning complex policies in high dimensional environments. This review summarises deep reinforcement learning (DRL) algorithms and provides a taxonomy of automated driving tasks where (D)RL methods have been employed, while addressing key computational challenges in real world deployment of autonomous driving agents. It also delineates adjacent domains such as behavior cloning, imitation learning, inverse reinforcement learning that are related but are not classical RL algorithms. The role of simulators in training agents, methods to validate, test and robustify existing solutions in RL are discussed. Index Terms—Deep reinforcement learning, Autonomous driving, Imitation learning, Inverse reinforcement learning, Controller learning, Trajectory optimisation, Motion planning, Safe reinforcement learning.
The main contributions of this work can be summarized as follows: ・Self-contained overview of RL background for the automotive community as it is not well known. ・Detailed literature review of using RL for different autonomous driving tasks. ・Discussion of the key challenges and opportunities for RL applied to real world autonomous driving. The rest of the paper is organized as follows.
Section II provides an overview of components of a typical autonomous driving system.
Section III provides an introduction to reinforcement learning and briefly discusses key concepts.
Section IV discusses more sophisticated extensions on top of the basic RL framework.
Section V provides an overview of RL applications for autonomous driving problems.
Section VI discusses challenges in deploying RL for real-world autonomous driving systems.
Section VII concludes this paper with some final remarks.
この表のキャプションは、OPEN-SOURCE FRAMEWORKS AND PACKAGES FOR STATE OF THE ART RL/DRL ALGORITHMS AND EVALUATION.(最先端のRL / DRLアルゴリズムと評価のためのオープンソースフレームワークとパッケージ。by Google翻訳)
Behaviour Suite for Reinforcement Learning Ian Osband, Yotam Doron, Matteo Hessel, John Aslanides, Eren Sezener, Andre Saraiva, Katrina McKinney, Tor Lattimore, Csaba Szepesvari, Satinder Singh, Benjamin Van Roy, Richard Sutton, David Silver, and Hado Van Hasselt, arXiv:1908.03568v3 [cs.LG] 14 Feb 2020 Abstract This paper introduces the Behaviour Suite for Reinforcement Learning, or bsuite for short. bsuite is a collection of carefully-designed experiments that investigate core capabilities of reinforcement learning (RL) agents with two objectives. First, to collect clear, informative and scalable problems that capture key issues in the design of general and efficient learning algorithms. Second, to study agent behaviour through their performance on these shared benchmarks. To complement this effort, we open source github.com/deepmind/bsuite, which automates evaluation and analysis of any agent on bsuite. This library facilitates reproducible and accessible research on the core issues in RL, and ultimately the design of superior learning algorithms. Our code is Python, and easy to use within existing projects. We include examples with OpenAI Baselines, Dopamine as well as new reference implementations. Going forward, we hope to incorporate more excellent experiments from the research community, and commit to a periodic review of bsuite from a committee of prominent researchers. このホワイトペーパーでは、強化学習のためのBehavior Suite、または略してbsuiteを紹介します。 bsuiteは、2つの目的を持つ強化学習(RL)エージェントのコア機能を調査する慎重に設計された実験のコレクションです。まず、一般的で効率的な学習アルゴリズムの設計における重要な問題を捉えた、明確で有益でスケーラブルな問題を収集します。次に、これらの共有ベンチマークでのパフォーマンスを通じてエージェントの動作を調査します。この取り組みを補完するために、私たちはオープンソース github.com/deepmind/bsuite。bsuite上のエージェントの評価と分析を自動化します。このライブラリは、RLの主要な問題に関する再現性のあるアクセス可能な研究を促進し、最終的には優れた学習アルゴリズムの設計を促進します。私たちのコードはPythonであり、既存のプロジェクト内で簡単に使用できます。 OpenAIベースライン、ドーパミン、および新しいリファレンス実装の例が含まれています。今後は、研究コミュニティからのより優れた実験を取り入れ、著名な研究者の委員会による定期的なbsuiteのレビューに取り組んでいきたいと考えています。by Google翻訳
Interest in artificial intelligence has undergone a resurgence in recent years. Part of this interest is driven by the constant stream of innovation and success on high profile challenges previously deemed impossible for computer systems. Improvements in image recognition are a clear example of these accomplishments, progressing from individual digit recognition (LeCun et al., 1998), to mastering ImageNet in only a few years (Deng et al., 2009; Krizhevsky et al., 2012). The advances in RL systems have been similarly impressive: from checkers (Samuel, 1959), to Backgammon (Tesauro, 1995), to Atari games (Mnih et al., 2015a), to competing with professional players at DOTA (Pachocki et al., 2019) or StarCraft (Vinyals et al., 2019) and beating world champions at Go (Silver et al., 2016). Outside of playing games, decision systems are increasingly guided by AI systems (Evans & Gao, 2016).
近年、人工知能への関心が復活しています。 この関心の一部は、以前はコンピュータシステムでは不可能と考えられていた注目を集める課題に対する革新と成功の絶え間ない流れによって推進されています。 画像認識の改善は、これらの成果の明確な例であり、個々の数字の認識(LeCun et al, 1998)からわずか数年でImageNetを習得する(Deng et al, 2009; Krizhevsky et al, 2012)まで進んでいます。 RLシステムの進歩も同様に印象的でした。チェッカー(Samuel, 1959)、バックギャモン(Tesauro, 1995)、アタリゲーム(Mnih et al, 2015a)、DOTAでのプロプレーヤーとの競争(Pachocki et al, 2019)またはStarCraft(Vinyals et al, 2019)およびGo(Silver et al, 2016)で世界チャンピオンを破っています。 ゲームをプレイする以外に、意思決定システムはますますAIシステムによって導かれています(Evans&Gao, 2016年)。by Google翻訳
As we look towards the next great challenges for RL and AI, we need to understand our systems better (Henderson et al., 2017). This includes the scalability of our RL algorithms, the environments where we expect them to perform well, and the key issues outstanding in the design of a general intelligence system. We have the existence proof that a single self-learning RL agent can master the game of Go purely from self-play (Silver et al., 2018). We do not have a clear picture of whether such a learning algorithm will perform well at driving a car, or managing a power plant. If we want to take the next leaps forward, we need to continue to enhance our understanding.
RLとAIの次の大きな課題に目を向けるとき、システムをよりよく理解する必要があります(Henderson et al, 2017)。 これには、RLアルゴリズムのスケーラビリティ、それらが適切に機能すると予想される環境、および未解決の主要な問題が含まれます。 一般的なインテリジェンスシステムの設計において。 単一の自己学習RLエージェントが純粋に自己プレイから囲碁のゲームを習得できるという存在証明があります(Silver et al, 2018)。 そのような学習アルゴリズムが車の運転や発電所の管理でうまく機能するかどうかについては、明確な見通しがありません。 次の飛躍を遂げたいのであれば、理解を深めていく必要があります。 by Google翻訳
1.1 Practical theory often lags practical algorithms:
The current theory of deep RL is still in its infancy. In the absence of a comprehensive theory, the community needs principled benchmarks that help to develop an understanding of the strengths and weakenesses of our algorithms.
Just as the MNIST dataset offers a clean, sanitised, test of image recognition as a stepping stone to advanced computer vision; so too bsuite aims to instantiate targeted experiments for the development of key RL capabilities.
1.3 Open source code, reproducible research
As part of this project we open source github.com/deepmind/bsuite, which instantiates all experiments in code and automates the evaluation and analysis of any RL agent on bsuite. This library serves to facilitate reproducible and accessible research on the core issues in reinforcement learning.
1.4 Related work
2 Experiments
2.1 Example experiment: memory length
読んで理解しようとしたが、課題が何なのか、次の語句が何なのか(DQNは見たことがあるという程度)、さっぱりわからない。 actor-critic with a recurrent neural network
In this chapter we will first explain what Reinforcement Learning is and what it's good at, then present two of the most important techniques in Deep Reinforcement Learning: polycy gradients and deep Q-networks (DQNs), including a discussion of Markov decision processes (MDPs).
Floris den Hengst et al., Data Science 3 (2020) 107–147
Abstract.
The major application areas of reinforcement learning (RL) have traditionally been game playing and continuous control. In recent years, however, RL has been increasingly applied in systems that interact with humans. RL can personalize digital systems to make them more relevant to individual users. Challenges in personalization settings may be different from challenges found in traditional application areas of RL. An overview of work that uses RL for personalization, however, is lacking. In this work, we introduce a framework of personalization settings and use it in a systematic literature review. Besides setting, we review solutions and evaluation strategies. Results show that RL has been increasingly applied to personalization problems and realistic evaluations have become more prevalent. RL has become sufficiently robust to apply in contexts that involve humans and the field as a whole is growing. However, it seems not to be maturing: the ratios of studies that include a comparison or a realistic evaluation are not showing upward trends and the vast majority of algorithms are used only once. This review can be used to find related work across domains, provides insights into the state of the field and identifies opportunities for future work. 強化学習(RL)の主な応用分野は、伝統的にゲームプレイと継続的な制御でした。しかし、近年、RLは人間と相互作用するシステムにますます適用されています。 RLは、デジタルシステムをパーソナライズして、個々のユーザーとの関連性を高めることができます。パーソナライズ設定の課題は、RLの従来のアプリケーション分野で見られる課題とは異なる場合があります。ただし、パーソナライズにRLを使用する作業の概要は不足しています。この作業では、パーソナライズ設定のフレームワークを紹介し、系統的文献レビューで使用します。設定に加えて、ソリューションと評価戦略を確認します。結果は、RLがパーソナライズの問題にますます適用され、現実的な評価がより一般的になっていることを示しています。 RLは、人間が関与するコンテキストに適用するのに十分な堅牢性を備えており、フィールド全体が成長しています。ただし、成熟していないようです。比較または現実的な評価を含む研究の比率は上昇傾向を示しておらず、アルゴリズムの大部分は1回しか使用されていません。このレビューは、ドメイン間で関連する作業を見つけるために使用でき、フィールドの状態への洞察を提供し、将来の作業の機会を特定します。by Google翻訳
Jess Whittlestone et al., Journal of Artificial Intelligence Research 70 (2021) 1003–1030
Abstract Deep Reinforcement Learning (DRL) is an avenue of research in Artificial Intelligence (AI) that has received increasing attention within the research community in recent years, and is beginning to show potential for real-world application. DRL is one of the most promising routes towards developing more autonomous AI systems that interact with and take actions in complex real-world environments, and can more flexibly solve a range of problems for which we may not be able to precisely specify a correct ‘answer’. This could have substantial implications for people’s lives: for example by speeding up automation in various sectors, changing the nature and potential harms of online influence, or introducing new safety risks in physical infrastructure. In this paper, we review recent progress in DRL, discuss how this may introduce novel and pressing issues for society, ethics, and governance, and highlight important avenues for future research to better understand DRL’s societal implications.
Deep Reinforcement Learning(DRL)は、近年研究コミュニティ内でますます注目を集めている人工知能(AI)の研究手段であり、実際のアプリケーションの可能性を示し始めています。 DRLは、複雑な実世界の環境と相互作用してアクションを実行する、より自律的なAIシステムを開発するための最も有望なルートのひとつであり、正しい答えを正確に特定できない可能性のあるさまざまな問題をより柔軟に解決できます。これは、人々の生活に大きな影響を与える可能性があります。たとえば、さまざまなセクターでの自動化の高速化、オンラインの影響の性質と潜在的な害の変化、物理インフラストラクチャへの新しい安全上のリスクの導入などです。このホワイトペーパーでは、DRLの最近の進歩を確認し、これが社会、倫理、ガバナンスに斬新で差し迫った問題をどのようにもたらすかについて説明し、DRLの社会的影響をよりよく理解するための将来の研究のための重要な手段を強調します。by Google翻訳
Wikipedia : Personalization (broadly known as customization) consists of tailoring a service or a product to accommodate specific individuals, sometimes tied to groups or segments of individuals. A wide variety of organizations use personalization to improve customer satisfaction, digital sales conversion, marketing results, branding, and improved website metrics as well as for advertising. Personalization is a key element in social media and recommender systems.
systematic literature review (SLR):この論文が、Reinforcement learning for personalizationの内容の論文をレビューしているのだと思ったが、SLRにRLを適用し、personalizationにLRを適用した文献の調査を行ったということなのだろうか。
Our discussion aims to provide important context and a clear starting point for the AI ethics and governance community to begin considering the societal implications of DRL in more depth.
The algorithm a software agent uses to determine its actions is called its policy. The policy could be a neural network taking observations as inputs and outputting the action to take (see Figure 18-2).
Figure 18-2. Reinforcement Learning using a neural network polycy:この図は何度も見ていたのだが、今日、ようやくこの模式図の意味するところがわかったように思う。
Structure prediction of surface reconstructions by deep reinforcement learning Søren A Meldgaard, Henrik L Mortensen, Mathias S Jørgensen and Bjørk Hammer
Abstract We demonstrate how image recognition and reinforcement learning combined may be used to determine the atomistic structure of reconstructed crystalline surfaces. A deep neural network represents a reinforcement learning agent that obtains training rewards by interacting with an environment. The environment contains a quantum mechanical potential energy evaluator in the form of a density functional theory program. The agent handles the 3D atomistic structure as a series of stacked 2D images and outputs the next atom type to place and the atomic site to occupy. Agents are seen to require 1000–10 000 single point density functional theory evaluations, to learn by themselves how to build the optimal surface reconstructions of anatase TiO2(001)-(1 × 4) and rutile SnO2(110)-(4 × 1).
Gaussian representation for image recognition and reinforcement learning of atomistic structure
Mads-Peter V Christiansen, Henrik Lund Mortensen, Søren Ager Meldgaard, and Bjørk Hammer, J Chem Phys. 2020 Jul 28;153(4):044107
Abstract The success of applying machine learning to speed up structure search and improve property prediction in computational chemical physics depends critically on the representation chosen for the atomistic structure. In this work, we investigate how different image representations of two planar atomistic structures (ideal graphene and graphene with a grain boundary region) influence the ability of a reinforcement learning algorithm [the Atomistic Structure Learning Algorithm (ASLA)] to identify the structures from no prior knowledge while interacting with an electronic structure program. Compared to a one-hot encoding, we find a radial Gaussian broadening of the atomic position to be beneficial for the reinforcement learning process, which may even identify the Gaussians with the most favorable broadening hyperparameters during the structural search. Providing further image representations with angular information inspired by the smooth overlap of atomic positions method, however, is not found to cause further speedup of ASLA.
Predictive Synthesis of Quantum Materials by Probabilistic Reinforcement Learning Pankaj Rajak, Aravind Krishnamoorthy, Ankit Mishra, Rajiv Kalia, Aiichiro Nakano and Priya Vashishta, arXiv.org > cond-mat > arXiv:2009.06739v1, [Submitted on 14 Sep 2020]
Abstract Predictive materials synthesis is the primary bottleneck in realizing new functional and quantum materials. Strategies for synthesis of promising materials are currently identified by time consuming trial and error approaches and there are no known predictive schemes to design synthesis parameters for new materials. We use reinforcement learning to predict optimal synthesis schedules, i.e. a time-sequence of reaction conditions like temperatures and reactant concentrations, for the synthesis of a prototypical quantum material, semiconducting monolayer MoS2, using chemical vapor deposition. The predictive reinforcement leaning agent is coupled to a deep generative model to capture the crystallinity and phase-composition of synthesized MoS2 during CVD synthesis as a function of time-dependent synthesis conditions. This model, trained on 10000 computational synthesis simulations, successfully learned threshold temperatures and chemical potentials for the onset of chemical reactions and predicted new synthesis schedules for producing well-sulfidized crystalline and phase-pure MoS2, which were validated by computational synthesis simulations. The model can be extended to predict profiles for synthesis of complex structures including multi-phase heterostructures and can also predict long-time behavior of reacting systems, far beyond the domain of the MD simulations used to train the model, making these predictions directly relevant to experimental synthesis.
Learning to grow: control of material self-assembly using evolutionary reinforcement learning Stephen Whitelam and Isaac Tamblyn, arXiv:1912.08333v3 [cond-mat.stat-mech] 28 May 2020
We show that neural networks trained by evolutionary reinforcement learning can enact efficient molecular self-assembly protocols. Presented with molecular simulation trajectories, networks learn to change temperature and chemical potential in order to promote the assembly of desired structures or choose between competing polymorphs. In the first case, networks reproduce in a qualitative sense the results of previously-known protocols, but faster and with higher fidelity; in the second case they identify strategies previously unknown, from which we can extract physical insight. Networks that take as input the elapsed time of the simulation or microscopic information from the system are both effective, the latter more so. The evolutionary scheme we have used is simple to implement and can be applied to a broad range of examples of experimental self-assembly, whether or not one can monitor the experiment as it proceeds. Our results have been achieved with no human input beyond the specification of which order parameter to promote, pointing the way to the design of synthesis protocols by artificial intelligence.
Generative Adversarial Networks for Crystal Structure Prediction Sungwon Kim, Juhwan Noh, Geun Ho Gu, Alan Aspuru-Guzik, and Yousung Jung ACS Cent. Sci. 2020, 6, 1412−1420
ABSTRACT: The constant demand for novel functional materials calls for efficient strategies to accelerate the materials discovery, and crystal structure prediction is one of the most fundamental tasks along that direction. In addressing this challenge, generative models can offer new opportunities since they allow for the continuous navigation of chemical space via latent spaces. In this work, we employ a crystal representation that is inversion-free based on unit cell and fractional atomic coordinates and build a generative adversarial network for crystal structures. The proposed model is applied to generate the Mg−Mn−O ternary materials with the theoretical evaluation of their photoanode properties for high-throughput virtual screening (HTVS). The proposed generative HTVS framework predicts 23 new crystal structures with reasonable calculated stability and band gap. These findings suggest that the generative model can be an effective way to explore hidden portions of the chemical space, an area that is usually unreachable when conventional substitutionbased discovery is employed.
agentのトレーニングには、working environmentが必要。そのためのsimulated environmentを提供するのがOpenAI Gym (Atari games, board games, 2D and 3D physical simulations, and so on)。
obsは1D NumPy arrayで、4つの数字が、obs[0]: cart's horizontal position (0.0 = center), obs[1]: its velocity (positive means right), obs[2]: the angle of the pole (0.0 = vertical), and obs[3]: its angular velocity (positive means clockwise)の順に並んでいる。
The step( ) method exacutes the given action and returns four values:
obs:
This is the new observation. The cart is now moving toward the right (obs[1] > 0). The pole is still tilted toward the right (obs[2] >0), but its angular velosity is now negative (obs[3] <0), so it will likely be tilted toward the left after the next step.
reward:
In this environment, you get a reward of 1.0 at every step, no matter what you do, so that the goal is to keep the episode running as long as possible.
done:
This value will be True when the episode is over. This will happen when the pole tilts too much, or goes off the screen, or after 200 steps (in this last case, you have won). After that, the environment must be reset before it can be used again.
info:
This environment-specific dictionary can provide some extra information that you may find useful for debugging or for training. For example, in some games it may indicate how many lives the agent has.
Fairseq is a sequence modeling toolkit written in PyTorch that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks.
Numba is an open source JIT compiler that translates a subset of Python and NumPy code into fast machine code.
pre-norm activation transformer:
Transformers without Tears: Improving the Normalization of Self-Attention
Toan Q. Nguyen and Julian Salazar, arXiv:1910.05895v2 [cs.CL] 30 Dec 2019
Abstract We evaluate three simple, normalizationcentric changes to improve Transformer training. First, we show that pre-norm residual connections (PRENORM) and smaller initializations enable warmup-free, validation-based training with large learning rates. Second, we propose `2 normalization with a single scale parameter (SCALENORM) for faster training and better performance. Finally, we reaffirm the effectiveness of normalizing word embeddings to a fixed length (FIXNORM). On five low-resource translation pairs from TED Talks-based corpora, these changes always converge, giving an average +1.1 BLEU over state-of-the-art bilingual baselines and a new 32.8 BLEU on IWSLT '15 EnglishVietnamese. We observe sharper performance curves, more consistent gradient norms, and a linear relationship between activation scaling and decoder depth. Surprisingly, in the highresource setting (WMT '14 English-German), SCALENORM and FIXNORM remain competitive but PRENORM degrades performance.
Show and Tell: A Neural Image Caption Generator Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan arXiv:1411.4555v2 [cs.CV] 20 Apr 2015
Abstract Automatically describing the content of an image is a fundamental problem in artificial intelligence that connects computer vision and natural language processing. In this paper, we present a generative model based on a deep recurrent architecture that combines recent advances in computer vision and machine translation and that can be used to generate natural sentences describing an image. The model is trained to maximize the likelihood of the target description sentence given the training image. Experiments on several datasets show the accuracy of the model and the fluency of the language it learns solely from image descriptions. Our model is often quite accurate, which we verify both qualitatively and quantitatively. For instance, while the current state-of-the-art BLEU-1 score (the higher the better) on the Pascal dataset is 25, our approach yields 59, to be compared to human performance around 69. We also show BLEU-1 score improvements on Flickr30k, from 56 to 66, and on SBU, from 19 to 28. Lastly, on the newly released COCO dataset, we achieve a BLEU-4 of 27.7, which is the current state-of-the-art.
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Kelvin Xu et al., arXiv:1502.03044v3 [cs.LG] 19 Apr 2016
Abstract Inspired by recent work in machine translation and object detection, we introduce an attention based model that automatically learns to describe the content of images. We describe how we can train this model in a deterministic manner using standard backpropagation techniques and stochastically by maximizing a variational lower bound. We also show through visualization how the model is able to automatically learn to fix its gaze on salient objects while generating the corresponding words in the output sequence. We validate the use of attention with state-of-theart performance on three benchmark datasets: Flickr8k, Flickr30k and MS COCO.
機械翻訳とオブジェクト検出の最近の研究に触発されて、画像の内容を説明することを自動的に学習する注意ベースのモデルを紹介します。 標準的なバックプロパゲーション手法を使用して、変分下限を最大化することにより確率的にこのモデルを決定論的にトレーニングする方法について説明します。 また、視覚化を通じて、出力シーケンスで対応する単語を生成しながら、モデルが顕著なオブジェクトを注視することを自動的に学習する方法を示します。 Flickr8k、Flickr30k、MS COCOの3つのベンチマークデータセットで、最新のパフォーマンスを使用してattentionの使用を検証します。 by Google翻訳
If we knew what the best action was at each step, we could train the neural network as usual, by minimizing the cross entropy between the estimated probability distribution and the target probability distribution.
It would just be regular supervised learning.
However, in Reinforcement Learning the only guidance the agent gets is through rewards, and rewards are typically sparce and delayed.
For example, if the agent manages to balance the pole for 100 steps, how can it know which of the 100 actions it took were good, and which of them were bad?
All it knows is that the pole fell after the last action, but surely this last action is not entirely responsible.
This is called the credit assignment problem: when the agent gets a reward, it is hard for it to know which actions should get credited (or blamed) for it.
Think of a dog that gets rewarded hours after it behaved well: will it understand what it is being rewarded for?
To tackle this problem, a common strategy is to evaluate an action based on the sum of all the rewards that come after it, usually applying a discount factor ɤ (gamma) at each step. discount gactorの意味、役割がわからんな。
This sum of discounted rewards is called the action's return. ここでのactionは、1 stepではなく、一連のstepの集合体を指しているようだ。
consider the example in Figure 18-6.
If an agent decides to go right three times in a row and gets +10 reward after the first step, 0 after the second step, and finally -50 after the third step, then assume we use a discount factor ɤ=0.8, the first action will have a return of 10 + ɤ x 0 + ɤ^2 x (-50) = -22.
If the discount factor is close to 0, then future rewards won't count for much compared to immediate rewards.
Conversely, if the discount factor is close to 1, then rewards far into the future will count almost as much as immediate rewards.
Typical discount factors vary from 0.9 to 0.99.
With a discount factor of 0.95, rewards 13 steps into the future count roughly for half as much as immediate rewards (since 0.95^13≒0.5), while with a discount factor of 0.99, rewards 69 steps into the future count for half as much as immediate rewards.
In the CartPole environment, actions have fairly short-term effects, so choosing a discount factor of 0.95 seems reasonable.
Figure 18-6. Computing an action's return: the sum of discounted future rewards
Of cource, a good action may be followed by several bad actions that cause the pole to fall quickly, resulting in the good action getting a low return (similarly, a good actor may sometimes star in a terrible movie).
However, if we play the game enough times, on average good actions will get a higher return than bad ones.
We want to estimate how much better or worse an action is, compared to the other possible actions, on average.
This is called the action average.
For this, we must run many episodes and normalize all the action returns (by subtracting the mean and dividing by the standard deviation).
After that, we can reasonably assume that actions with a negative advantage were bad while actions with a positive advantage were good.
Perfect - now that we have a way to evaluate each action, we are ready to train our first agent using polycy gradients.
Let's see how.
Policy Gradients
As discusses earlier, PG algorithms optimize the parameters of a polycy by following the gradients toward higher rewards.
One popular class of GP algorithms, called REINFORCE algorithms, was introduced back in 1992 (https://homl.info/132) by Ronald Williams.
そのような背景から、現在ではRNNを取り除く研究(もしくは並列計算可能なRNNの研究)が活発に行われています。これは『Attention is all you need』というタイトルの論文で提案された手法です。そのタイトルが示すとおり、RNNではなくAttentionを使って処理します。ここでは、このTransformerについて簡単に見ていきます。
Choosing an appropriate image size is difficult, as complex molecules will need a high resolution to preserve details, but training on 2.4 million in high resolution is unfeasable. The chosen resolution of 256*448 should preserve enough detail and allow for training on a TPU within the 3 hours limit.
A. Geron氏のテキストには、Glorot and He initialization, LeCun initialization, Xavier initializationなどが紹介されている。今使っているSegmentation Modelsでは、これらの initializationには対応していないようである。
random initialization(epochs=30):LB=0.819 :意外に健闘しているようにみえる。
ここまで、"An activation function to apply after the final convolution layer. "をNoneにして、 score > 0、で評価してきたが、activation functionを"sigmoid"にして、score > thresholdとして、thresholdの最適化をやってみる。
ちょっとやってみたが、うまくいかない。何かおかしい。間違ったことをしているかもしれない・・・。
best single modelというタイトルのdiscussionにおいて、LB=0.84+から0.86+くらいのスコアのモデル(encoder+decoder)、optimizer、loss function、epochsなど概要が紹介されている。自分の結果、0.83+とは最大で0.03くらい違う。前処理、後処理などの情報が少ないので何を参考にすればよいのかわからないが、気になるのは、スコアが高い0.85+の4件が、EncoderにEfficientNetを使っていないことと、開発年代の古いEncoderを用いて、エポック数を多くしていることである。さらに、resnet34-UnetでLB=0.857というスコアを得ているのは驚きだ。FPNは1件で、そのほかはUnetを使っている。
Googleが昨年発表した論文"EfficientDet: Scalable and Efficient Object Detection"で提案している新しいモデルEfficientDetは、FPNから派生したもののようである"we propose a weighted bi-directional feature pyramid network (BiFPN)"。
Bristol-Myers Squibb – Molecular Translation Can you translate chemical images to text?
chemical imagesというのは構造式、textというのは、InChIのこと。構造式は画像として与えられる。InCHIについて、wikipediaの説明は以下の通り。
InChI(International Chemical Identifier)は、標準的かつ人間が読める方法で分子情報を提供し、またウェブ上でのデータベースからの情報の検索機能を提供する。元々、2000年から2005年にIUPACとNISTによって開発され、フォーマットとアルゴリズムは非営利であり、開発の継続は、IUPACも参画する非営利団体のInChI Trustにより、2010年までサポートされていた。現在の1.04版は、2011年9月にリリースされた。
1.04版の前までは、ソフトウェアはオープンソースのGNU Lesser General Public Licenseで無償で入手できたが[3]、現在は、IUPAC-InChI Trust Licenseと呼ばれる固有のライセンスとなっている[4]。ウイキペディアより引用。
Deep Semantic Segmentation of Natural and Medical Images: A Review Saeid Asgari Taghanaki, Kumar Abhishek, Joseph Paul Cohen, Julien Cohen-Adad and Ghassan Hamarneh, arXiv:1910.07655v3 [cs.CV] 3 Jun 2020,
Cross Entropy --> Weighted Cross Entropy --> Focal Loss (Lin et al. (2017b) added the term (1 − pˆ)γ to the cross entropy loss)
Overlap Measure based Loss Functions:Dice Loss / F1 Score --> Tversky Loss(Tversky loss (TL) (Salehi et al., 2017) is a generalization of the DL(Dice Loss) --> Exponential Logarithmic Loss --> Lovasz-Softmax loss(a smooth extension of the discrete Jaccard loss(IoU loss))
上記のような種々の損失関数の解説の最後に次のように書かれている。
The loss functions which use cross-entropy as the base and the overlap measure functions as a weighted regularizer show more stability during training.
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam Google Inc. ECCV 2018
Abstract.
Spatial pyramid pooling module or encode-decoder structure are used in deep neural networks for semantic segmentation task. The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information.
In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network.
Microsoft COCO: Common Objects in Context Tsung-Yi Lin Michael Maire Serge Belongie Lubomir Bourdev Ross Girshick James Hays Pietro Perona Deva Ramanan C. Lawrence Zitnick Piotr Dollar´
arXiv:1405.0312v3 [cs.CV] 21 Feb 2015 Abstract—We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complexeveryday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328k images, the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.
Panoptic segmentation aims to unify the typically distinct tasks of semantic segmentation (assign a class label to each pixel) and instance segmentation (detect and segment each object instance). Existing metrics are specialized for either semantic or instance segmentation and cannot be used to evaluate the joint task involving both stuff and thing classes. Rather than using a heuristic combination of disjoint metrics for the two tasks, the panoptic task introduces a new Panoptic Quality (PQ) metric. PQ evaluates performance for all categories, including both stuff and thing categories, in a unified manner.
Panoptic Leaderboardのトップのチームのpaper
Joint COCO and Mapillary Workshop at ICCV 2019: Panoptic Segmentation Challenge Track Technical Report: Explore Context Relation for Panoptic Segmentation Shen Wang1,2∗ Tao Liu1,3∗ Huanyu Liu1∗ Yuchen Ma1 Zeming Li1 Zhicheng Wang1 Xinyu Zhou1 Gang Yu1 Erjin Zhou1 Xiangyu Zhang1 Jian Sun
次は、損失関数だが、上記のReviewには、「The loss functions which use cross-entropy as the base and the overlap measure functions as a weighted regularizer show more stability during training.」と書かれていた。今使っているものでいえば、overlap系はDice, Jaccard, Lovaszとなる。試してみるしかないのだろう。MAnetの論文では、BCEとDiceの比率は1対4であったように思う。Diceをベースに、BCEを加えている。LB=0.836を得ているのは全て、DiceLossのみなので、手始めに、MAnetの論文をまねてみるのもよいかもしれない。
We've got a new private test set incoming. Some of the old test samples will be moved to train. The process is currently underway and may take some time.Submissions are disabled while this is taking place. We will notify you when the update is complete. Thank you for your patience!
UNet_3Plus.pyには、UNet_3Plusの他に、Unet_3Plus_DeepSupとUnet_3Plus_DeepSup_CGMが含まれている。それぞれ、ベースコード、with deep supervision、with deep supervision and class-guided moduleであり、論文中で追加機能として説明されているものである。
import torch import torch.nn as nn import torch.nn.functional as F from layers import unetConv2, unetUp, unetUp_origin from init_weights import init_weights from torchvision import models import numpy as np
UNet.pyをnotebookにコピペして走らせてみると、次のメッセージが出て停止した。
ModuleNotFoundError: No module named 'layers'
from layers import unetConv2, unetUp, unetUp_origin:ここでひっかかっている。
上記のLB=0.916の公開コードでは、loss=bce_dice or bce_jaccard, となっているが、コードをよく見ると、bce_weight=1となっているので、BCE一択のようである。これは、自分の最近の経験と一致する。すなわち、DiceLossとJaccardLossは、activationを"sigmoid"にすると、自分が使っているコードでは、全く機能しない。
Furthermore, there is a certain elegance to the rhythm of these cycles and it simplifies the decision of when to drop learning rates and when to stop the current training run. Experiments show that replacing each step of a constant learning rate with at least 3 cycles trains the network weights most of the way and running for 4 or more cycles will achieve even better performance. Also, it is best to stop training at the end of a cycle, which is when the learning rate is at the minimum value and the accuracy peaks.
Leslie N. Smith氏の論文の表を見ると、エポック数を25、50、75、100、150と増やせば、確実に、スコアは上がっている。データ量が多い場合はこういう傾向になるのだろう。他方で、データ量が少ないときには、20エポックくらいで、CyclicLRやOneCycleLRが良い結果を与えることを、実験して確かめているようだ。
scale_fn (function) – Custom scaling policy defined by a single argument lambda function, where 0 <= scale_fn(x) <= 1 for all x >= 0. If specified, then ‘mode’ is ignored. Default: None
非常に気になったので、"super convergence deep learning" で検索したら、Super-Convergenceを理論的に解明した(らしい)論文があった。
Super-Convergence with an Unstable Learning Rate Samet Oymak∗, arXiv:2102.10734v1 [cs.LG] 22 Feb 2021 Abstract Conventional wisdom dictates that learning rate should be in the stable regime so that gradient-based algorithms don’t blow up. This note introduces a simple scenario where an unstable learning rate scheme leads to a super fast convergence, with the convergence rate depending only logarithmically on the condition number of the problem. Our scheme uses a Cyclical Learning Rate where we periodically take one large unstable step and several small stable steps to compensate for the instability. These findings also help explain the empirical observations of [Smith and Topin, 2019] where they claim CLR with a large maximum learning rate leads to “super-convergence”. We prove that our scheme excels in the problems where Hessian exhibits a bimodal spectrum and the eigenvalues can be grouped into two clusters (small and large). The unstable step is the key to enabling fast convergence over the small eigen-spectrum.
従来の通念では、勾配ベースのアルゴリズムが爆発しないように、学習率は安定した状態にある必要があります。 このノートでは、不安定な学習率スキームが超高速収束につながる単純なシナリオを紹介します。収束率は、問題の条件数に対数的にのみ依存します。 私たちのスキームは、不安定性を補うために、定期的に1つの大きな不安定なステップといくつかの小さな安定したステップを実行する循環学習率を使用します。 これらの調査結果は、[Smith and Topin、2019]の経験的観察を説明するのにも役立ちます。ここでは、最大学習率が高いCLRが「超収束」につながると主張しています。 私たちのスキームは、ヘッセ行列が二峰性スペクトルを示し、固有値を2つのクラスター(小さいものと大きいもの)にグループ化できる問題に優れていることを証明します。 不安定なステップは、小さな固有スペクトルでの高速収束を可能にするための鍵です。(Google翻訳)
Super-Convergence with an Unstable Learning Rate Samet Oymak∗, arXiv:2102.10734v1 [cs.LG] 22 Feb 2021
Our scheme uses a Cyclical Learning Rate where we periodically take one large unstable step and several small stable steps to compensate for the instability.
one large unstable step and several small stable steps
GRADIENT DESCENT ON NEURAL NETWORKS TYPICALLY OCCURS AT THE EDGE OF STABILITY Jeremy Cohen Simran Kaur Yuanzhi Li J. Zico Kolter1 and Ameet Talwalkar2 Carnegie Mellon University and: 1Bosch AI 2 Determined AI Correspondence to: jeremycohen@cmu.edu
arXiv:2103.00065v1 [cs.LG] 26 Feb 2021, Published as a conference paper at ICLR 2021
F. Chollet氏のテキストの犬と猫の分類で、500枚づつのデータを使用するとoverfittingによってaccuracyが0.7くらいで頭打ちになり、augmentationでデータ数を増やすことによって、0.85くらいまで上がるということから、augmentationの効果を体感するというのがあった。
AutoML: A Survey of the State-of-the-Art Xin He, Kaiyong Zhao, Xiaowen Chu, arXiv:1908.00709v6 [cs.LG] 16 Apr 2021
Abstract Deep learning (DL) techniques have obtained remarkable achievements on various tasks, such as image recognition, object detection, and language modeling. However, building a high-quality DL system for a specific task highly relies on human expertise, hindering its wide application. Meanwhile, automated machine learning (AutoML) is a promising solution for building a DL system without human assistance and is being extensively studied. This paper presents a comprehensive and up-to-date review of the state-of-the-art (SOTA) in AutoML. According to the DL pipeline, we introduce AutoML methods –– covering data preparation, feature engineering, hyperparameter optimization, and neural architecture search (NAS) –– with a particular focus on NAS, as it is currently a hot sub-topic of AutoML. We summarize the representative NAS algorithms’ performance on the CIFAR-10 and ImageNet datasets and further discuss the following subjects of NAS methods: one/two-stage NAS, one-shot NAS, joint hyperparameter and architecture optimization, and resource-aware NAS. Finally, we discuss some open problems related to the existing AutoML methods for future research.
概要 ディープラーニング(DL)技術は、画像認識、オブジェクト検出、言語モデリングなどのさまざまなタスクで目覚ましい成果を上げています。ただし、特定のタスクのために高品質のDLシステムを構築することは、人間の専門知識に大きく依存しており、その幅広いアプリケーションを妨げています。一方、自動機械学習(AutoML)は、人間の支援なしでDLシステムを構築するための有望なソリューションであり、広く研究されています。このホワイトペーパーでは、AutoMLの最先端(SOTA)の包括的で最新のレビューを紹介します。 DLパイプラインによると、現在AutoMLのホットなサブトピックであるため、NASに特に焦点を当てて、データ準備、機能エンジニアリング、ハイパーパラメータ最適化、ニューラルアーキテクチャ検索(NAS)をカバーするAutoMLメソッドを紹介します。 CIFAR-10およびImageNetデータセットでの代表的なNASアルゴリズムのパフォーマンスを要約し、NASメソッドの次の主題についてさらに説明します:1/2ステージNAS、ワンショットNAS、共同ハイパーパラメータとアーキテクチャの最適化、およびリソース認識NAS。最後に、将来の研究のために、既存のAutoMLメソッドに関連するいくつかの未解決の問題について説明します。 by Google翻訳
2.3. Data Augmentation To some degree, data augmentation (DA) can also be regarded as a tool for data collection, as it can generate new data based on the existing data. However, DA also serves as a regularizer to avoid over-fitting of model training and has received more and more attention. Therefore, we introduce DA as a separate part of data preparation in detail. Figure 3 classifies DA techniques from the perspective of data type (image, audio, and text), and incorporates automatic DA techniques that have recently received much attention. For image data, the affine transformations include rotation, scaling, random cropping, and reflection; the elastic transformations contain the operations like contrast shift, brightness shift, blurring, and channel shuffle; the advanced transformations involve random erasing, image blending, cutout [89], and mixup [90], etc. These three types of common transformations are available in some open source libraries, like torchvision 5, ImageAug [91], and Albumentations [92]. In terms of neural-based transformations, it can be divided into three categories: adversarial noise [93], neural style transfer [94], and GAN technique [95].
THE BREAK-EVEN POINT ON OPTIMIZATION TRAJECTORIES OF DEEP NEURAL NETWORKS Stanisław Jastrz˛ebski, Maciej Szymczak, Stanislav Fort, Devansh Arpit, Jacek Tabor Kyunghyun Cho, Krzysztof Geras, Published as a conference paper at ICLR 2020
ABSTRACT The early phase of training of deep neural networks is critical for their final performance. In this work, we study how the hyperparameters of stochastic gradient descent (SGD) used in the early phase of training affect the rest of the optimization trajectory. We argue for the existence of the “break-even" point on this trajectory, beyond which the curvature of the loss surface and noise in the gradient are implicitly regularized by SGD. In particular, we demonstrate on multiple classification tasks that using a large learning rate in the initial phase of training reduces the variance of the gradient, and improves the conditioning of the covariance of gradients. These effects are beneficial from the optimization perspective and become visible after the break-even point. Complementing prior work, we also show that using a low learning rate results in bad conditioning of the loss surface even for a neural network with batch normalization layers. In short, our work shows that key properties of the loss surface are strongly influenced by SGD in the early phase of training. We argue that studying the impact of the identified effects on generalization is a promising future direction.
Abstract The vast majority of successful deep neural networks are trained using variants of stochastic gradient descent (SGD) algorithms. Recent attempts to improveSGD can be broadly categorized into two approaches: (1) adaptive learning rate schemes, such as AdaGrad and Adam, and (2) accelerated schemes, such as heavy-ball and Nesterov momentum. In this paper, we propose a new optimization algorithm, Lookahead, that is orthogonal to these previous approaches and iteratively updates two sets of weights. Intuitively, the algorithm chooses a search direction by looking ahead at the sequence of “fast weights" generated by another optimizer. We show that Lookahead improves the learning stability and lowers the variance of its inner optimizer with negligible computation and memory cost. We empirically demonstrate Lookahead can significantly improve the performance of SGD and Adam, even with their default hyperparameter settings on ImageNet, CIFAR- 10/100, neural machine translation, and Penn Treebank.
<雑談>今使っているコードはKerasで書かれていて、callbacksが使えるレベルまでには理解できていないことに気付き、F. Chollet氏のDeep Learningのテキストを読み返すことにした。画像処理分野は、Chapter 5のDeep Learning for computer visionまで勉強していたが、Chapter 7のAdvanced deep-learning best practicesは、殆ど読んでいなかった。7.2に面白い記述がある。大きなデータセットに対してmodel.fit( )またはmodel.fit_generator( )を用いて何十エポックものトレーニングの計算をすることは、紙飛行機を飛ばすようなもので、一旦手を離れると飛行経路も着陸位置も制御できない。これに対して、紙飛行機ではなくドローンを飛ばせば、環境情報を把握することができ、その情報をオペレータに伝えることによって状況に即した飛行をさせることができる。それがcallbacksの機能ということである。keras.callbacksとして、ModelCheckpoint, EarlyStopping, LearningRateScheduler, ReduceLROnPlateau, CSVLoggerなどの説明が続く。
TPU:バッチ数を多くすることによる高速化のイメージがある。Flower Classification with TPUsというコンペで、チュートリアルモデルでは、128バッチで計算していて、Adamを用い、学習率は0.00001からスタートし、5エポックくらいで0.0004まで上げ、12エポックで0.00011くらいまで下げるというような感じであった。なんだかCyclicLRに似ている。
HuBMAP:1,162 teams, 3 days to go:昨日より、400チームくらい少なくなっている。何がおきたのだろうか。データセットを更新する前の状態のまま放置しているチームがいなくなったようだ。自分のsubmit回数も、そのぶん、減っている。ということで、母数が減ったのでメダル圏内に該当するチーム数が40ほど減った。それゆえ、一気にメダル圏外に押し出され、やる気が失せた。残念だな。
TTAによって追加する画像の種類と枚数を決める基準は何だろう。 Chris Deotteさんが、枚数に対して効果をプロットとしていたような記憶がある。12~15枚がピークだったような気がする。モデルやハイパーパラメータ、augmentationの内容によって、効果は違うと思うので、自分で実験することが重要。
Similar to what Data Augmentation is doing to the training set, the purpose of Test Time Augmentation is to perform random modifications to the test images. Thus, instead of showing the regular, “clean” images, only once to the trained model, we will show it the augmented images several times. We will then average the predictions of each corresponding image and take that as our final guess [1].
データ拡張がトレーニングセットに対して行っていることと同様に、テスト時間拡張(Test Time Augmentation)の目的は、テストイメージにランダムな変更を実行することです。 したがって、通常の「クリーンな」画像をトレーニング済みモデルに1回だけ表示する代わりに、拡張画像を数回表示します。 次に、対応する各画像の予測を平均し、それを最終的な推測として使用します[1]。by Google翻訳
HuBMAPコンペサイトに、TTAを非常にわかりやすく、具体的に説明したcodeが公開されている。Let's Understand TTA in Segmentation by @joshi98kishan
この図面はすばらしい!
github.com/qubvel/ttachに説明されている手順:reverse transformations for each batch of masks/labels、の意味が一目でわかって納得した。図中では、文字が小さくて読み取りにくいが、TTA in Segmentationのすぐ下に、Deaugmentationと書かれている。
TPUs in Code Competitions Due to technical limitations for certain kinds of code-only competitions we aren’t able to support notebook submissions that run on TPUs, made clear in the competition's rules. But that doesn’t mean you can’t use TPUs to train your models!
A workaround to this restriction is to run your model training in a separate notebook that uses TPUs, and then to save the resulting model. You can then load that model into the notebook you use for your submission and use a GPU to run inference and generate your predictions.
data augmentationの本質を理解するためには、教師データの本質を理解している必要がある。機械学習モデルは、labelの正確さを超えることはない。画像とlabelは、pixelレベルで1対1に正しく対応していなければならない。機械学習モデルは、画像とlabelの対応関係を根拠として、新たな画像に対して、labelを推測する。labelが正確でない場合、機械学習モデルは、正確でないlabelを推測する。
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates Leslie N. Smith, Nicholay Topin, arXiv:1708.07120v3 [cs.LG] 17 May 2018
Abstract In this paper, we describe a phenomenon, which we named “super-convergence”, where neural networks can be trained an order of magnitude faster than with standard training methods. The existence of super-convergence is relevant to understanding why deep networks generalize well. One of the key elements of super-convergence is training with one learning rate cycle and a large maximum learning rate. A primary insight that allows super-convergence training is that large learning rates regularize the training, hence requiring a reduction of all other forms of regularization in order to preserve an optimal regularization balance. We also derive a simplification of the Hessian Free optimization method to compute an estimate of the optimal learning rate. Experiments demonstrate super-convergence for Cifar-10/100, MNIST and Imagenet datasets, and resnet, wide-resnet, densenet, and inception architectures. In addition, we show that super-convergence provides a greater boost in performance relative to standard training when the amount of labeled training data is limited. The architectures to replicate this work will be made available upon publication.
While deep neural networks have achieved amazing successes in a range of applications, understanding why stochastic gradient descent (SGD) works so well remains an open and active area of research. Specifically, we show that, for certain hyper-parameter values, using very large learning rates with the cyclical learning rate (CLR) method [Smith, 2015, 2017] can speed up training by as much as an order of magnitude. We named this phenomenon “super-convergence.” In addition to the practical value of super-convergence training, this paper provides empirical support and theoretical insights to the active discussions in the literature on stochastic gradient descent (SGD) and understanding generalization.
ディープニューラルネットワークはさまざまなアプリケーションで驚くべき成功を収めていますが、確率的勾配降下法(SGD)がうまく機能する理由を理解することは、オープンで活発な研究分野です。具体的には、特定のハイパーパラメータ値について、循環学習率(CLR)法[Smith、2015、2017]で非常に大きな学習率を使用すると、トレーニングを1桁も高速化できることを示します。 この現象を「超収束」と名付けました。 超収束トレーニングの実用的な価値に加えて、この論文は、確率的勾配降下法(SGD)と一般化の理解に関する文献での活発な議論に対する経験的サポートと理論的洞察を提供します。 by Google翻訳
Compounding the Performance Improvements of Assembled Techniques in a Convolutional Neural Network Jungkyu Lee, Taeryun Won, Tae Kwan Lee, Hyemin Lee, Geonmo Gu, Kiho Hong
ResNeSt: Split-Attention Networks Hang Zhang et al., arXiv:2004.08955v2 [cs.CV] 30 Dec 2020
7. Conclusion This work proposes the ResNeSt architecture that leverages the channel-wise attention with multi-path representation into a single unified Split-Attention block. The model universally improves the learned feature representations to boost performance across image classification, object detection, instance segmentation and semantic segmentation. Our Split-Attention block is easy to work with (i.e., dropin replacement of a standard residual block), computationally efficient (i.e., 32% less latency than EfficientNet-B7 but with better accuracy), and transfers well. We believe ResNeSt can have an impact across multiple vision tasks, as it has already been adopted by multiple winning entries in 2020 COCO-LVIS challenge and 2020 DAVIS-VOS chanllenge.
EfficientDet: Scalable and Efficient Object Detection Mingxing Tan, Ruoming Pang, and Quoc V. Le, arXiv:1911.09070v7 [cs.CV] 27 Jul 2020
While our EfficientDet models are mainly designed for object detection, we are also interested in their performance on other tasks such as semantic segmentation. Following [19], we modify our EfficientDet model to keep feature level fP2; P3; :::; P7g in BiFPN, but only use P2 for the final per-pixel classification. For simplicity, here we only evaluate a EfficientDet-D4 based model, which uses a ImageNet pretrained EfficientNet-B4 backbone (similar size to ResNet-50). We set the channel size to 128 for BiFPN and 256 for classification head. Both BiFPN and classification head are repeated by 3 times.
Pyramid scene parsing network H Zhao, J Shi, X Qi, X Wang… - Proceedings of the IEEE …, 2017 - openaccess.thecvf.com
Abstract Scene parsing is challenging for unrestricted open vocabulary and diverse scenes. In this paper, we exploit the capability of global context information by different-regionbased context aggregation through our pyramid pooling module together with the proposed pyramid scene parsing network (PSPNet). Our global prior representation is effective to produce good quality results on the scene parsing task, while PSPNet provides a superior framework for pixellevel prediction. The proposed approach achieves state-ofthe-art performance on various datasets. It came first in ImageNet scene parsing challenge 2016, PASCAL VOC 2012 benchmark and Cityscapes benchmark. A single PSPNet yields the new record of mIoU accuracy 85.4% on PASCAL VOC 2012 and accuracy 80.2% on Cityscapes.
今回のモデルでは、TTA無しのときの予測時間が12.5分で、4枚追加すると予測には、45分くらいかかっている。仮に5つのモデルをアンサンブルすると、45x5=225分かかる。よくわかっていないのだが、submit中に、予測はprivate_dataに対しても行われ、private_dataがtest_dataの1.4倍ある場合には、225 x 2.4=540分=9時間となる。B0でギリギリなので、大きなモデルを使うには、アンサンブルするモデルの数を減らす、TTAの枚数を減らす、ということをする必要がある。B5などでは、予測時間が長くなって、とても使えそうにないと思う。
AutoAlbument is an AutoML tool that learns image augmentation policies from data using the Faster AutoAugment algorithm. It relieves the user from manually selecting augmentations and tuning their parameters. AutoAlbument provides a complete ready-to-use configuration for an augmentation pipeline.
AutoAlbument supports image classification and semantic segmentation tasks. The library requires Python 3.6 or higher.
Your challenge is to detect functional tissue units (FTUs) across different tissue preparation pipelines. An FTU is defined as a “three-dimensional block of cells centered around a capillary, such that each cell in this block is within diffusion distance from any other cell in the same block” (de Bono, 2013). The goal of this competition is the implementation of a successful and robust glomeruli FTU detector.:Descriptionより
The focus of HuBMAP is understanding the intrinsic intra-, inter-, and extra- cellular biomolecular distribution in human tissue. HuBMAP will focus on fresh, fixed, or frozen healthy human tissue using in situ and dissociative techniques that have high-spatial resolution.
The HubMAP Data Portal aims to be an open map of the human body at the cellular level. These tools and maps are openly available, to accelerate understanding of the relationships between cell and tissue organization and function and human health.
The kidney images and their segmentation masks, both of anatomical structures and glomeruli, were generated by HuBMAP’s tissue mapping center at Vanderbilt University (TMC-VU) team at the BIOmolecular Multimodal Imaging Center (BIOMIC). The glomeruli masks were further improved to provide a "gold standard" by the Indiana University team through a combination of manual and machine learning efforts. Any annotations of glomeruli that were considered incorrect, ambiguous, or originating from damaged portions of the images were removed.
"This Github page explains how to use the output of ilastik classification in segmentation .tiff files and obtain disease scores per glomeruli."「このGithubページでは、セグメンテーション.tiffファイルでilastik分類の出力を使用して、糸球体ごとの疾患スコアを取得する方法について説明します。グーグル翻訳」
この"ilastik classification"について調べてみた。
"Leverage machine learning algorithms to easily segment, classify, track and count your cells or other experimental data. Most operations are interactive, even on large datasets: you just draw the labels and immediately see the result. No machine learning expertise required."
Glomerulus Classification and Detection Based on Convolutional Neural Networks † Jaime Gallego, Anibal Pedraza, Samuel Lopez, Georg Steiner, Lucia Gonzalez, Arvydas Laurinavicius and Gloria Bueno
In this paper we propose two methods devoted to: Glomerulus classification and Glomerulus detection. In the Glomerulus classification proposal (Method I), we study the viability of the CNN to achieve a correct Glomerulus classification into Glomerulus/non-Glomerulus classes. In the Glomerulus detection method (Method II), we use the CNN configuration that gave the best results and performance for Glomerulus classification (Method I) to achieve the Glomeruli detection in a WSI. In this proposal, we present a method suitable for PAS samples belonging to different laboratories, thanks to color normalization process used in the data augmentation step. Our method uses a sliding window with overlapping to perform the detection, and utilizes a majority vote decision for each pixel to reduce false positive detections. With this proposal, we achieve a detection score of93.7%, which improves upon the results obtained in reference methods.
The convolutional neural networks implemented in this paper consist of U-Net, DenseNet, LSTM-GCNet, and 2D V-Net. All of these architectures receive images with labels, and output the corresponding predictions. UNet [33], consists of several contracting paths to capture context and symmetric expanding paths which enable precise segmentation and location.
Looking in links: ./
Processing /kaggle/input/qubvelsegmentationmodelspytorch
Requirement already satisfied: torchvision>=0.3.0 in /opt/conda/lib/python3.7/site-packages (from segmentation-models-pytorch==0.1.3) (0.8.1)ERROR: Could not find a version that satisfies the requirement pretrainedmodels==0.7.4 (from segmentation-models-pytorch)
ERROR: No matching distribution found for pretrainedmodels==0.7.
Modifying a Notebook-specific Environment It is also possible to modify the Docker container associated with the current Notebook image.
Using a standard package installer In the Notebook Editor, make sure "Internet" is enabled in the Settings pane (it will be by default if it's a new notebook).
For Python, you can run arbitrary shell commands by prepending ! to a code cell. For instance, to install a new package using pip, run !pip install my-new-package. You can also upgrade or downgrade an existing package by running !pip install my-existing-package==X.Y.Z.
Googleで検索し、ダウンロードサイトhttps://pypi.org/project/pretrainedmodels/ に行って、ファイルをダウンロードし、Kaggle のDatasetサイトの、+ New Datasetをクリックし、ダウンロードしたファイルを、フォルダーごと、Drag and drop files to uploadのスペースに移動する。データセットに名前を付けて、Createボタンをクリックすれば出来上がり。Createボタンの横にあるボタンで、PrivateかPublicかを選んでおく。
Review: U-Net (Biomedical Image Segmentation) Sik-Ho Tsang, Nov 5, 2018·5 min read
Since unpadded convolution is used, output size is smaller than input size. Instead of downsizing before network and upsampling after network, overlap tile strategy is used. Thereby, the whole image is predicted part by part as in the figure above. The yellow area in the image is predicted using the blue area. At the image boundary, image is extrapolated by mirroring.
Since the training set can only be annotated by experts, the training set is small. To increase the size of training set, data augmentation is done by randomly deformed the input image and output segmentation map.
それぞれ次のように説明されている。The PAB is used to model the feature interdependencies in spatial dimensions, which capture the spatial dependencies between pixels in a global view. In addition, the MFAB is to capture the channel dependencies between any feature map by multi-scale semantic feature fusion.
引用文献を示していなかった。
表2と表3の両方に、U-Netがある。表2のU-Netはオリジナルで、表3のU-Netは``Liver segmentation in CT images using three dimensional to two dimensional fully convolutional network"というタイトルの論文中で次のような模式図で表されている。
Training Deep Networks with Stochastic Gradient Normalized by Layerwise Adaptive Second Moments, Boris Ginsburg et al., arXiv:1905.11286v3 [cs.LG] 6 Feb 2020
In all experiments, NovoGrad performed equally or better than SGD and Adam/AdamW. NovoGrad is more robust to the initial learning rate and weight initialization than other methods. For example, NovoGrad works well without LR warm-up, while other methods require it. NovoGrad performs exceptionally well for large batch training, e.g. it outperforms other methods for ResNet-50 for all batches up to 32K. In addition, NovoGrad requires half the memory compared to Adam.
NovoGrad and all models in this paper are open sourced.
>>> optimizer=torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)>>> scheduler=ReduceLROnPlateau(optimizer,'min')>>> forepochinrange(10):>>> train(...)>>> val_loss=validate(...)>>> # Note that step should be called after validate()>>> scheduler.step(val_loss)
Prior to PyTorch 1.1.0, the learning rate scheduler was expected to be called before the optimizer’s update; 1.1.0 changed this behavior in a BC-breaking way. If you use the learning rate scheduler (calling scheduler.step()) before the optimizer’s update (calling optimizer.step()), this will skip the first value of the learning rate schedule. If you are unable to reproduce results after upgrading to PyTorch 1.1.0, please check if you are calling scheduler.step() at the wrong time.
... the Transformer, which significantly improved the state of the art in NMT without using any recurrent or convolutional layers, just attention mechanisms (plus embedding layers, dense layers, normalization layers, and a few other bits and pieces).
F. Chollet氏のテキストに、AttentionやTransformerは無い。と思う。やはり、古いのだ。これに比して、A. Geron氏のテキスト(第2版:TF2)は、TF2というだけあって、2019年の前半くらいまでの情報が含まれていて、GPTやBERTも紹介されている。AnacondaにTF2がインストールできず、かつ、英語力も不足していたので、A. Geron氏のテキストを十分学べず、知らないことが多すぎるだけでなく、自分の勝手な解釈も多いことがわかってきた。目の前の話だと、encoder-decoderの理解の問題。variational auto encoderの印象が強くて、encoder-decoderに対して本来の意味とは全く異なるイメージを抱いていたようだ。情けないことだが、これが現実なのだ。
A. Geron氏のテキストでは、Figure 15-4にEncoder-Decoder networks、Figure 16-6にEncoder-Decoder network with an attention model、Figure 16-8にTransformer architecture、Figure 16-10にMulti-Head Attention layer architectureがそれぞれ図示されている。これで、encode-decoderとattentionとtransformerがつながった。
question.csvのpartは、Kaggleのデータの説明に、the relevant section of the TOEIC test.と書いてあるので、上記の1~7を指すのだろうが、lectures.csvのpartは、top level category code for the lectureと説明されていて、よくわからない。
今のモデルの現状は、LB=0.736である。
来週末までに、流すデータを見直して、0.74+にしたいと思う。
12月6日(日)
Riiid!:2,383 teams, a month to go : gold 0.797+, silver 0.776+
An RNN can simultaneously take a sequence of inputs and produce a sequence of outputs. this type of sequence-to-sequence network is useful for predicting time series such as stock prices: you feed the prices over tha last N days, and it must output the prices shifted by one day into the future.
Alternatively, you could feed the network a sequence of inputs and ignore all outputs except for the last one. In other words, this is a sequence-to-vector network. For example, you could feed the network a sequence of words corresponding to a movie review, and the network would output a sentiment score (e.g., from -1 [hate] to +1 [love]).
Conversely, you could feed the network the same input vectorover and over again at each time step and let it output a sequence. This is a vector-to-sequence network. For example, the input could be an image (or the output of a CNN), and the output could be a caption for that image.
Lastly, you could have a sequence-to-vector network, called an encoder, followed by a vector-to-sequence network called a decoder. For example, this could be used for translating a sentence from one language to another. You would feed the network a sentence in one language, the encoder would convert this sentence into a single vector representation, and then the decoder would decode this vector into a sentence in another language. This two-step model, called an Encoder-Decoder, works much better than trying to translate on the fly with a single sequence-sequence RNN: the last words of a sentence can affect the first words of the translation, so you need to wait untill you have seen the whole sentence before translating it. We will see how to implement an Encoder-Decoder in Chapter 16.
ふむふむ。なんとなく、Encoder-Decoderのことがわかってきたような気がする。
A. Geronさんのテキストの第16章 Natural Language Processing with RNNs and Atentionを理解しよう。
全40ページだ。
読書百遍義自ずから見る、といきますか。ちなみに「見る」は「あらわる」と読む。
で、読んでいるのだが、tokenizer, GRU, embedding, LSTM, ...勉強不足でわからん。Chapter 15: Processing Sequencies Using RNNs and CNNsにもどらないと、・・・。
With all this, you can get good translations for fairly short sentences (esoecially if you use pretrained word embeddings). Unfortunately, this model will be really bad at translationg long sentences. Once again, the problem comes from the limited short term memory of RNNs. Attention mechanisms are the game-changing innovation that addressed this problem.
F. CholletさんのテキストもA. Geronさんのテキストも英文のまま読んでいる。コードが英文で書かれているので、とにかく、英単語が日本語に変換することなくすっと頭に入るようになりたいと思ってそうしているのだが、それにはデメリットもある。とにかく、進むのが遅い。それと、今、訳本を読み始めて感じたのだが、英語のテキストだと本文を読むのに疲れて、コードへの集中力が高まらない。対して訳本は、コードに集中できる。原著だと、コードを理解するために本文を読むのは英英辞典を使うようなものだが、訳本だと、コードを理解するときに、コードの英単語にはかなり慣れてきて辞書は要らないので、コードの機能を理解することに集中できるというメリットがある。結局は、学習の積み重ねが重要ということになるのかな。
even_numbers = [x for x in range(5) if x % 2 == 0] # [0, 2, 4]
squares = [x * x for x in range(5)] # [0, 1, 4, 9, 16]
even_squares = [x * x for x in even_numbers] # [0, 4, 16]
square_dict = { x : x * x for x in range(5)} # { 0:0, 1:1, 2:4, 3:9, 4:16 }
square_set = { x * x for x in [1, -1]} # { 1 }
簡単な表現で十分に慣れておけば、実際の場面でも理解できるようになるだろう。
アンダースコア "_" も慣れておけば、出くわしたときに、あわてなくてすむ。
zeros = [ 0 for _ in even_numbers ] # even_numbersと同じ長さの0が続くリスト
Training data-efficient image transformers & distillation through attention Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve J ´ egou ´, Facebook AI, Sorbonne University
Abstract
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification.
However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, thereby limiting their adoption by the larger community.
In this work, with an adequate training scheme, we produce a competitive convolution-free transformer by training on Imagenet only.
We train it on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external data. We share our code and models to accelerate community advances on this line of research.
Additionally, we introduce a teacher-student strategy specific to transformers.
It relies on a distillation token ensuring that the student learns from the teacher through attention.
We show the interest of this tokenbased distillation, especially when using a convnet as a teacher.
This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 84.4% accuracy) and when transferring to other tasks.
importpandasaspdimportnumpyasnpdf=pd.read_csv('data/src/sample_pandas_normal.csv',index_col=0)df['sex']=['female',np.nan,'male','male','female','male']df['rank']=[2,1,1,0,2,0]print(df)# age state point sex rank# name # Alice 24 NY 64 female 2# Bob 42 CA 92 NaN 1# Charlie 18 CA 70 male 1# Dave 68 TX 70 male 0# Ellen 24 CA 88 female 2# Frank 30 NY 57 male 0
An Empirical Analysis of Feature Engineering for Predictive Modeling Jeff Heaton, SoutheastCon 2016, 2016 - ieeexplore.ieee.org
I. INTRODUCTION Feature engineering is an essential but labor-intensive component of machine learning applications [1].Most machinelearning performance is heavily dependent on the representation of the feature vector. As a result, data scientists spend much of their effort designing preprocessing pipelines and data transformations [1]. To utilize feature engineering, the model must preprocess its input data by adding new features based on the other features [2]. These new features might be ratios, differences, or other mathematical transformations of existing features. This process is similar to the equations that human analysts design. They construct new features such as body mass index (BMI), wind chill, or Triglyceride/HDL cholesterol ratio to help understand existing features’ interactions. Kaggle and ACM’s KDD Cup have seen feature engineering play an essential part in several winning submissions. Individuals applied feature engineering to the winning KDD Cup 2010 competition entry [3]. Additionally, researchers won the Kaggle Algorithmic Trading Challenge with an ensemble of models and feature engineering. These individuals created these engineered features by hand.
... the following sixteen selected engineered features: • Counts • Differences • Distance Between Quadratic Roots • Distance Formula • Logarithms • Max of Inputs • Polynomials • Power Ratio (such as BMI) • Powers • Ratio of a Product • Rational Differences • Rational Polynomials • Ratios • Root Distance • Root of a Ratio (such as Standard Deviation) • Square Roots
Francois Chollet “Developing good models requires iterating many times on your initial ideas, up until the deadline; you can always improve your models further. Your final models will typically share little in common with the solutions you envisioned when first approaching the problem, because a-priori plans basically never survive confrontation with experimental reality.”
チューニングが行き詰ってきたこともあり、LightGBMのマニュアルの ”Parameters Tuning"を参考に、num_leavesとmin_data_in_leafとmax_depthを用いて、条件検討をやりなおすことにした。num_leavesしか使っていなかったので、他の2つは適当に値を設定してやってみたら、10時間くらいで、なんとなくそれらしい結果が出始めた。そこで、submitではなく、記録のためにcommitしたら、commitの途中で、"[Worning] No further splits with positive gain, best gain: -inf"というメッセージが現れた。これはダメだろうと思い、中断して、調べたら、min_data_in_leafの設定値、1024が大きすぎることによるものであるらしい、ということがわかった。
マニュアルには、大きなデータの場合には数百もしくは数千で十分"In practice, setting it to hundreds or thousands is enough for a large dataset".とあったので、間をとって1024にしたのだが、この1024が不適切だったようだ。
Tune Parameters for the Leaf-wise (Best-first) Tree
LightGBM uses the leaf-wise tree growth algorithm, while many other popular tools use depth-wise tree growth. Compared with depth-wise growth, the leaf-wise algorithm can converge much faster. However, the leaf-wise growth may be over-fitting if not used with the appropriate parameters.
To get good results using a leaf-wise tree, these are some important parameters:
num_leaves. This is the main parameter to control the complexity of the tree model. Theoretically, we can set num_leaves=2^(max_depth) to obtain the same number of leaves as depth-wise tree. However, this simple conversion is not good in practice. The reason is that a leaf-wise tree is typically much deeper than a depth-wise tree for a fixed number of leaves. Unconstrained depth can induce over-fitting. Thus, when trying to tune the num_leaves, we should let it be smaller than 2^(max_depth). For example, when the max_depth=7 the depth-wise tree can get good accuracy, but setting num_leaves to 127 may cause over-fitting, and setting it to 70 or 80 may get better accuracy than depth-wise.
min_data_in_leaf. This is a very important parameter to prevent over-fitting in a leaf-wise tree. Its optimal value depends on the number of training samples and num_leaves. Setting it to a large value can avoid growing too deep a tree, but may cause under-fitting. In practice, setting it to hundreds or thousands is enough for a large dataset.
max_depth. You also can usemax_depth to limit the tree depth explicitly.