一昨日から、Using AI to accelerate scientific discovery - Demis Hassabis (Crick Insight Lecture Series)、のビデオを聴講している。
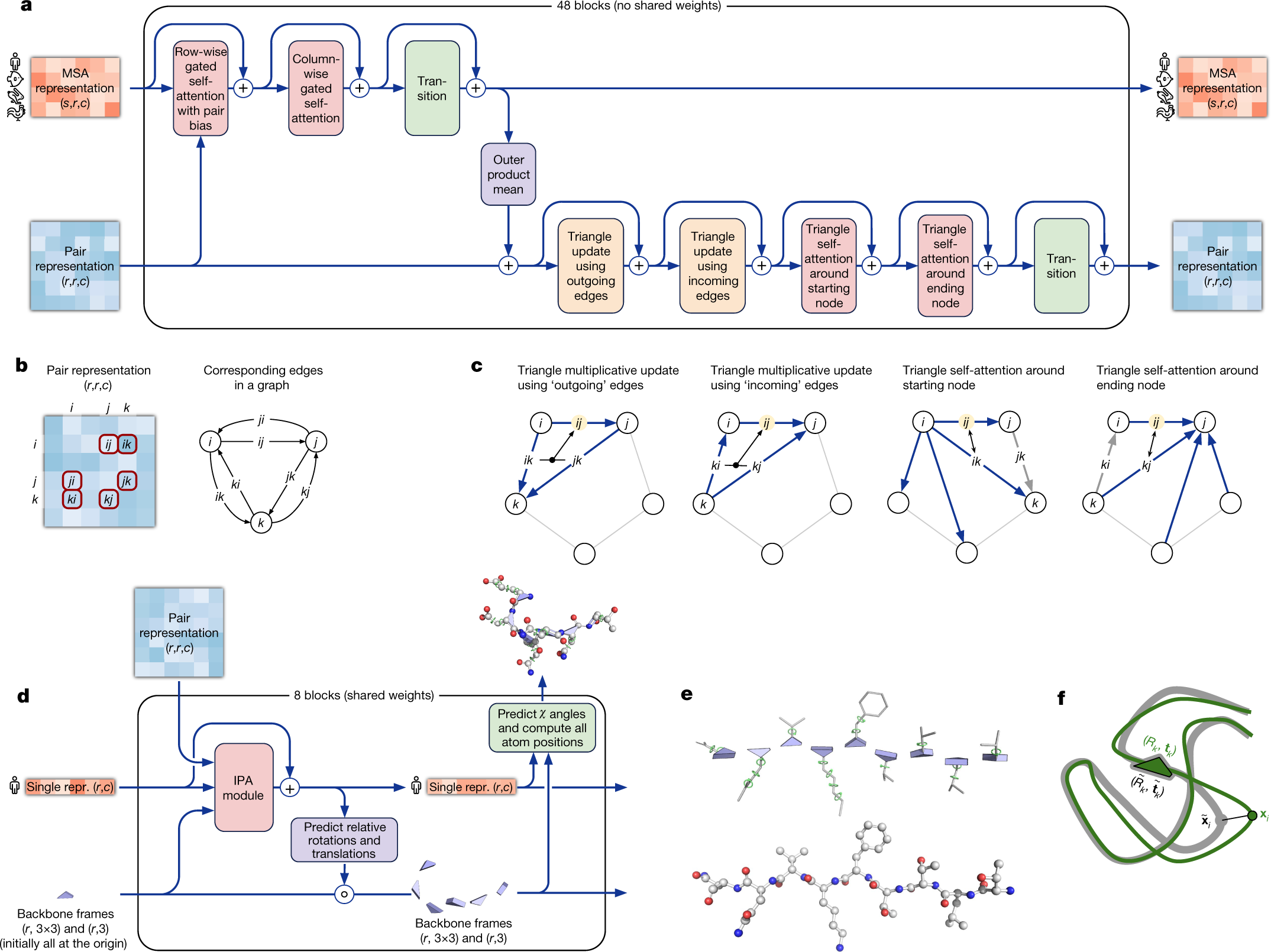
AlphaFoldは”32 component algorithms and 60 pages of SI”と説明されている(SI:supplemental information)。約20名が5年間をかけて開発しており、domain knowledgeを用いているので、AGIではないと述べている。
どのようなものなのか、論文をみてみよう。
Highly accurate protein structure prediction with AlphaFold
John Jumper et al., Nature, Vol 596, (2021) 583
Training with labelled and unlabelled data The AlphaFold architecture is able to train to high accuracy using only supervised learning on PDB data, but we are able to enhance accuracy (Fig. 4a) using an approach similar to noisy student self-distillation35. In this procedure, we use a trained network to predict the structure of around 350,000 diverse sequences from Uniclust3036 and make a new dataset of predicted structures filtered to a high-confidence subset. We then train the same architecture again from scratch using a mixture of PDB data and this new dataset of predicted structures as the training data, in which the various training data augmentations such as cropping and MSA subsampling make it challenging for the network to recapitulate the previously predicted structures. This self-distillation procedure makes effective use of the unlabelled sequence data and considerably improves the accuracy of the resulting network. Additionally, we randomly mask out or mutate individual residues within the MSA and have a Bidirectional Encoder Representations from Transformers (BERT)-style37 objective to predict the masked elements of the MSA sequences. This objective encourages the network to learn to interpret phylogenetic and covariation relationships without hardcoding a particular correlation statistic into the features. The BERT objective is trained jointly with the normal PDB structure loss on the same training examples and is not pre-trained, in contrast to recent independent work.
良質な3次元構造データベースPDB(Protein Data Bank)が存在するということが大前提だということだろう。
Machine learning on neutron and x-ray scattering and spectroscopies Zhantao Chen, Nina Andrejevic, Nathan C. Drucker, et al. Chem. Phys. Rev. 2, 031301 (2021)
・internal structure representation is very basic - no options mor molecules, rigid groupes, bond length/angle relations, no internal support for representation as space group with asymmetric unit
・limited math support within constraint formulas
・no way to adjust PDF calculations by user-defined profile functions or improved peak-width formulas
・no option to incorporate other informations soueces (theory or experiment) into optimization
・PDF-calculation engine PDFfit2 is hard to maintain or extend