Kaggleに挑戦-18
Peking University/Baidu - Autonomous Driving
Can you predict vehicle angle in different settings?
*1月21日の締め切りに向けて、お手本のプログラムコードを理解し、動かす。
*ゼロから作るのスローガンで始めたが、Kaggleにべったりに変更中である。ゼロから作ろうとすることの良さと損失、まねることによる効率と損失、いろいろあるが、一人でやっていると、種々の組合せが必要なのかなと思う。
・APTOS2019は、よくがんばったと思うが、反省は、データの前処理ができなかったことであり、その後の、細胞認識、医療診断画像認識などでも前処理が克服できなかった。それがあって、金属表面欠陥の検出と分類では、前処理に注力し、モデルの構築も論文に学ぶことから始めたが、中途半端に終わっている。
・課題は殆ど積み残しているが、目標である、自分のモデルを開発すること、からは、ぶれないようにしたいと思っている。
*さて、今日は、Kaggleのkernelでお手本モデルを動かすことと、ゼロ点覚悟で、推測結果を提出することだ!
・Kaggleのkernelを使うといっても、ただ動かしているだけ。過去に使ったモデルの行き先も、計算結果の行き先もまだわかっていないし、中断したプログラムの行方もわからない。つまり、使いっぱなしで、蓄積がない。
*2019年6月にF. Chollet氏のDeep Learning with Pythonを読み始め、8月にAPTOS2019に挑戦したので、Kaggleは5か月になる。なのに、Kaggleのリーダーボードに残っているのは、学習用のコンペ、Housing Prices Competition for Kaggle Learn Usersのみで、3638/18904となっている。それも、Kaggleの学習コース中に練習問題で出てきて、指示されたとおりにやったようなもの。
*少なくとも、Kaggleのkernelについては、もう少し使えるようにならないと、と思って、ググってみた。
・出てきたのは、カレーちゃんのYouTube。前から知っていたけど、あえて見なかったのだが、さきほど、初期のものと思われるものを視聴した。殆ど知っている内容だったが、新たに学んだのは●Commitしないとコードも出力ファイルも残らないということと、出力ファイルの場所がわかったことである。役に立った。
・カレーちゃんの後に、Preferred Networksの秋葉氏が昨年の3月3日にシンポジウムで講演された、Kaggle画像分類コンテストへのアプローチ、を視聴してみた。2つのコンペで、いずれも1桁順位だったとのこと。すごいもんだ。非常に良く考えられているのと、かなり正直に話されていることに好感をもてた。当人も言われているが、高得点狙いの技術にすぎないものもあって、それらの技術は、本質的な進歩に直接にはつながるものではないかもしれないが、その経験によって、目の前にある技術が、本質的な進歩につながるものか否かを識別する能力が身につくことが、Kaggle挑戦で上位入賞した経験の大きな利点かなと感じた。
・過学習とその解消、汎化性能の向上への取り組みは、本質的に重要である。加えて、秋葉氏の講演の2つ目の話題、誤認させる技術と、誤認しない技術のコンペは、コンペ自体が、画像認識技術の発展において非常に本質的な問題提起をしているとともに、当該分野の進歩を促す良いコンペだと感じた。
*人は、画像を、あらゆる解像度、焦点距離、色相で捉えているので、画像認識ソフトも、それを積極的に取り入れたものにするのが良いと思う。と書きながら、変分オートエンコーダやGANなど、すでにそうなっているように感じるが、並列処理とか分散処理とか、組織化とか、抽象化とか、概念化とか、いろいろなヒトの能力を個別に具体化することの積み重ねから、本物の人工知能がつくられていくんだろうな。
*commit待ちをしていると、さらに次の動画が出てきた。松尾先生の2015年のご講演で、
*お手本のコード、計算に約3時間かかったので、Comittも同じくらいかかる。途中でKernelが停止しないか心配だ。1回目は、Commitの途中でキャンセルして結果が残らず、2回目は夜中に計算させていたが朝見るとkernelが停止していて何も残らず。3回目は、今朝立ち上げて、今、Commit中である。
*commitが完了したので、お手本で得られた結果をそのまま、submittした。恥ずかしいことであるが、次に進むためのステップにすることを前提にしたものであることを肝に銘じておく。
*1st/46 Cell:
パッケージ、モジュールのimport:Anacondaには、condaを使って、cv2とpytorchをインストールした。
*2nd/46 Cell:
train.csvとsample_submission.csvをpandasにより読み込む。pd.read_csv()
opencvに、カメラキャリブレーションと3次元再構成の説明がある。それによると、(cx, cy)は主点(通常は画像中心)、fx, fyはピクセル単位で表される焦点距離である。
お手本では、camera_intrinsic.txtに与えられているfx, fy, cx, cyを、3 x 3の行列に入れるとともに、その逆行列をつくっている。次の式で使われている記号と同じ。
次の式で、(X, Y, Z)は、ワールド座標系の3次元座標を表し、(u, v)は、画像平面に投影された点の座標を表す。
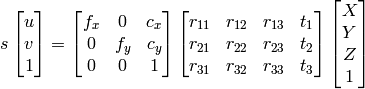
*3rd/46 Cell:
cv2.imread()による画像の読み込み:OpenCVの関数imread()で画像ファイルを読み込むと色の順番がBGR(青、緑、赤)になる。
そのため、RGBに変換している:img = np.array(img[:, :, ::-1])
img.shape:(2710,3384, 3)
*4th/46 Cell:
train.csvのデータをpandasで読み込み、コンマと空白で区切られた文字列を、 [ { 'id': , 'yaw': , 'pitch': , 'roll': , 'x': , 'y': , 'z': } ]の形式のディクショナリに変換する関数 str2coords の定義。わずか7行の見事なコード。作りたかったコードが目の前にある。次からは自分で作れるように、しっかり学ぼう。
def str2coords(s, names=[ 'id', 'yaw', 'pitch', 'roll', 'x', 'y', 'z' ]):
coords = [ ]
for l in np.array(s.split()).reshape([-1, 7]):
coords.append(dict(zip(names, l.astype('float'))))
if 'id' in coords[-1]:
coords[-1]['id'] = int(coords[-1]['id'])
return coords
・s は、train['PredictionString']の1枚の画像中の複数台の車の配置情報(文字列string)
・for I in np.array(s.split()).reshape([-1, 7]):7つの文字列毎に、7つの文字列を分離して、配列にしたものから、数の文字stringを順に取り出す。
・dict(zip(list1, list2)):list1とlist2をzipで統合してdictで辞書型にする。
*5th/46 Cell :
1枚の画像中の複数台の車の配置情報 inp=train['PredictionString'][0] を4/46に送り、それを辞書に変換した結果 str2coords(inp) を表示して、文字列情報が配置情報に正しく変換されているかどうかを確認するもの。
*6/46 Cell :
1枚の画像に写っている車の台数の分布図を描くコード。
lens = [len(str2coords(s)) for s in train['PredictionString']]
この1行のコードで、train.csv中の全画像について、各画像における車の台数の1次元配列が得られる。
sns.countplot(lens)でヒストグラムが得られる。
すごいね。ただただ感心するほかない!
つづく

