KaggleのARCコンペ第3位、Ilia Larchwnko氏の手法に学ぶ
目的は、Domein Specific Languageにより、課題を解くことができるようにすること。
ARCコンペの7位以内で、かつ、GitHubで公開しているものの中から選んだ。
Ilia氏は、2名で参加していて、最終結果は0.813(19/104)であるが、GitHubで公開しているのは、Ilia氏単独のもので、単独での正解数は正確にはわからない。
Kaggleのコンペサイトに公開されているnotebooksは、19/104の好成績を得ているものであるが、複数のコードが混ざっている。
GitHubに公開されている、Ilia氏単独開発のコードは、全体の構成がわかりやすい。train dataでの正解は138/400、evaluation dataでの正解は96/400とのことである。
ソースコードは、大きくは、predictors(約4500行)とpreprocessing(約1300行)とfunctions(約160行)に分かれている。
predictorsでは、functionsから、
1.
combine_two_lists(list1, list2):
2.
filter_list_of_dicts(list1, list2):
""" returns the intersection of two lists of dicts """
3.
find_mosaic_block(image, params):
""" predicts 1 output image given input image and prediction params """
4.
intersect_two_lists(list1, list2):
""" intersects two lists of np.arrays """
5.
reconstruct_mosaic_from_block(block, params, original_image=None):
6.
swap_two_colors(image):
""" swaps two colors """
preprocessingからは、
1.
find_color_boundaries(array, color):
""" looks for the boundaries of any color and returns them """
2.
find_glid(image, frame=False, possible_colors=None):
""" looks for the grid in image and returns color and size """
3.
get_color(color_dict, colors):
""" retrive the absolute number corresponding a color set by color_dict """
4.
get_color_max(image, color):
""" return the part of image inside the color boundaries """
5.
get_dict_hash(d):
6.
get_grid(image, grid_size, cell, frame=False):
""" returns the particular cell form the image with grid """
7.
get_mask_from_block_params(image, params, block_cashe=None, mask_cashe=None, color_scheme=None)
8.
get_predict(image, transform, block_cash=None, color_scheme=None):
""" applies the list of transforms to the image """
9.
preprosess_sample(sample, param=None, color_param=None, process_whole_ds=False):
""" make the whole preprocessing for particular sample """
が呼び出され、
predictorsには、以下のクラスがある。
1. Predictor
2.
Puzzle(Predictor):
""" Stack different blocks together to get the output """
3.
PuzzlePixel(puzzle):
""" very similar to puzzle but applicable only to pixel_level blocks """
4.
Fill(predictor):
""" applies different rules using 3x3 masks """
5.
Fill3Colors(Predictor):
""" same as Fill but iterates over 3 colors """
6.
FillWithMask(Predictor):
""" applies rules based on masks extracted from images """
7.
FillPatternFound(Predictor):
""" applies rules based on masks extracted from images """
8.
ConnectDot(Predictor):
""" connect dot of same color, on one line """
9.
ConnectDotAllColors(Predictor):
""" connect dot of same color, on one line """
10
FillLines(Predictor):
""" fill the whole horizontal and/or vertical lines of one color """
11.
ReconstructMosaic(Predictor)
""" reconstruct mosaic """
12.
ReconstructMosaicRR(Predictor):
""" reconstruct mosaic using rotations and reflections """
13.
ReconstructMosaicExtract(ReconstructMosaic):
""" returns the reconstructed part of the mosaic """
14.
ReconstructMosaicRRExtract(ReconstructMosaicRR):
""" returns the reconstructed part of the rotate/reflect mosaic """
15.
Pattern(Predictor)
""" applies pattern to every pixel with particular color """
16.
PatternFromBlocks(Pattern):
""" applies pattern extracted form some block to every pixel with particular color """
17.
Gravity(Predictor):
""" move non_background pixels toward something """
18.
GravityBlocks(Predictor):
""" move non_background objects toward something """
19.
GravityBlocksToColors(GravityBlocks):
""" move non_background objects toward color """
20.
GravityToColor
21. EliminateColor
22. EliminateDuplicate
23. ReplaceColumn
24. CellToColumn
25. PutBlochIntoHole
26. PutBlockOnPixel
27. EliminateBlock
28. InsideBlock
29. MaskToBlock
30. Colors
31. ExtendTargets
32. ImageSlicer
33. MaskToBlockParallel
34. RotateAndCopyBlock
わかりやすい課題を1つ選んで、詳細を見ていこう。
まず最初に、入力として与えられたもの(イメージ、図柄、グリッドパターン)の、colorと、blockと、maskを、JSON-like objectで表現する。
JSONの文法は、こんな感じ。
{ "name": "Suzuki", "age": 22}
それぞれ、以下のように説明されている。
しかし、これだけ見ても、なかなか、理解できない。
実際のパターンと見比べたり、preprocessing.pyのコードを見て学んでいくしかない。
この作業は、ARCの本質的な部分でもあるので、じっくり検討しよう。
2.1.1 Colors
I use a few ways to represent colors; below are some of them:
-
Absolute values. Each color is described as a number from 0 to 9. Representation:
{"type”: "abs”, "k”: 0} - あらかじめ決められている数字と色の対応関係:0:black, 1:blue, 2:red, 3:green, 4:yellow, 5:grey, 6:magenda, 7:orange, 8:sky, 9:brown
-
The numerical order of color in the list of all colors presented in the input image sorted (ascending or descending) by the number of pixels with these colors. Representation:
{"type”: "min”, "k”: 0},{"type”: "max”, "k”: 0} - 色の並び、0(黒)を最大とみなすか、最小とみなすか。どういう使い方をするのだろうか。
-
The color of the grid if there is one on the input image. Representation:
{"type”: "grid_color”} - 単色(出力に単色はあるが、入力で単色というのはあっただろうか)。それとも、黒地に単色パターンという意味だろうか。
-
The unique color in one of the image parts (top, bottom, left, or right part; corners, and so on). Representation:
{"type": "unique", "side": "right"},{"type": "unique", "side": "tl"},{"type": "unique", "side": "any"} - 上下左右隅のどこかの部分の色だけが異なっている。"tl"は、top+leftのことだろうか?
-
No background color for cases where every input has only two colors and 0 is one of them for every image. Representation:
{"type": "non_zero"} - 入力グリッドが2色からなっている場合に、通常は、0:黒をバックグラウンドとして扱うが、黒が他の色と同じように扱われている場合には、"non_zero"と識別するということか。
Etc.
2.1.2 Blocks
Block is a 10-color image somehow derived from the input image.
Each block is represented as a list of dicts; each dict describes some transformation of an image.
One should apply all these transformations to the input image in the order they are presented in the list to get the block.
Below are some examples.
The first order blocks (generated directly from the original image):
-
The image itself. Representation:
[{"type": "original"}] -
One of the halves of the original image. Representation:
[{"type": "half", "side": "t"}],[{"type": "half", "side": "b"}],[{"type": "half", "side": "long1"}] - 上半分、下半分、"long1":意味不明
- "t" : top, "b" : bottom
-
The largest connected block excluding the background. Representation:
[{"type": "max_block", "full": 0}] - バックグラウンド以外で、もっとも大きなブロックに着目する、ということか。"full": 0は、バックグラウンドが黒(0)ということか?
-
The smallest possible rectangle that covers all pixels of a particular color. Representation:
[{"type": "color_max", "color": color_dict}]color_dict – means here can be any abstract representation of color, described in 2.1.1. - 特定の色で最小サイズの矩形ブロックのことか?"color_max"の意味が不明
-
Grid cell. Representation:
[{"type": "grid", "grid_size": [4,4],"cell": [3, 1],"frame": True}] - グリッドが全体で、セルは部分を指しているのか?
-
The pixel with particular coordinates. Representation:
[{"type": "pixel", "i": 1, "j": 4}] - particular coordinateとi,jの関係が不明
Etc.
The second-order blocks – generated by applying some additional transformations to the other blocks:
-
Rotation. Representation:
[source_block ,{"type": "rotation", "k": 2}]source_blockmeans that there can be one or several dictionaries, used to generate some source block from the original input image, then the rotation is applied to this source block - 回転、"k"は単位操作の繰り返し回数か?
-
Transposing. Representation:
[source_block ,{"type": "transpose"}] - "transpose" : 行と列を入れ替える
-
Edge cutting. Representation:
[source_block ,{"type": "cut_edge", "l": 0, "r": 1, "t": 1, "b": 0}]In this example, we cut off 1 pixel from the left and one pixel from the top of the image. - 端部のカット:数字がピクセル数だとすれば、rightとtopから1ピクセルカットするということになる。説明が間違っているのか?
-
Resizing image with some scale factor. Representation:
[source_block , {"type": "resize", "scale": 2}],[source_block , {"type": "resize", "scale": 1/3}] - 2倍、3分の1倍
-
Resizing image to some fixed shape. Representation:
[source_block , {"type": "resize_to", "size_x": 3, "size_y": 3}] - x方向に3倍、y方向にも3倍ということか?
-
Swapping some colors. Representation:
[source_block , {"type": "color_swap", "color_1": color_dict_1, "color_2": color_dict_2}] - 色の交換
Etc.
- There is also one special type of blocks -
[{"type": "target", "k": I}]. It is used when for the solving ot the task we need to use the block not presented on any of the input images but presented on all target images in the train examples. Please, find the example below. - 次の図のように、入力画像に含まれず、出力画像(target)にのみ含まれるブロック構造を指す。

2.1.3 Masks
Masks are binary images somehow derived from original images. Each mask is represented as a nested dict.
-
Initial mask literally:
block == color. Representation:{"operation": "none", "params": {"block": bloc_list,"color": color_dict}}bloc_list here is a list of transforms used to get the block for the mask generation -
Logical operations over different masks Representation:
{"operation": "not", "params": mask_dict}, {"operation": "and", "params": {"mask1": mask_dict 1, "mask2": mask_dict 2}}, {"operation": "or", "params": {"mask1": mask_dict 1, "mask2": mask_dict 2}}, {"operation": "xor", "params": {"mask1": mask_dict 1, "mask2": mask_dict 2}} -
Mask with the original image's size, representing the smallest possible rectangle covering all pixels of a particular color. Representation:
{"operation": "coverage", "params": {"color": color_dict}} -
Mask with the original image's size, representing the largest or smallest connected block excluding the background. Representation: {"operation": "max_block"}
オリジナルイメージサイズのマスクの例
オリジナルイメージを4x4に拡大した後に、オリジナルイメージでマスクしている!

以下の2組もマスクの例


You can find more information about existing abstractions and the code to generate them in preprocessing.py.
2.2 Predictors
I have created 32 different classes to solve different types of abstract task using the abstractions described earlier.
All of them inherit from Predictor class.
The general logic of every predictor is described in the pseudo-code below (also, it can be different some classes).
for n, (input_image, output_image) in enumerate(sample['train']):
list_of_solutions = [ ]
for possible_solution in all_possible_solutions:
if apply_solution(input_image, possible_solution) == output_image:
list_of_solutions.append(possible_solution)
if n == 0:
final_list_of_solutions = list_of_solutions
else:
final_list_of _solutions = intersection(list_of_solutions, final_list_of _solutions)
if len(final_list_of_solutions == 0
return None
answers = [ ]
for test_input_image in sample['test']:
answers.append([ ])
for solution in final_list_of_solutions:
answers[-1].append(apply_solution(test_input_image, solution))
return answers
The examples of some predictors and the results are below.
・Puzzle - generates the output image by concatenating blocks generated from the input image
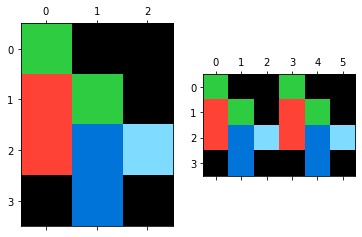
見た目は非常に簡単なのだが、プログラムは130行くらいある。
まずは、写経
# puzzle like predictors
class Puzzle(Predictor):
""" Stack different blocks together to get the output """
def __init__(self, params=None, preprocess_params=None):
super( ).__init__(params, preprocess_params)
self.intersection = params["intersection"]
def initiate_factors(self, target_image):
t_n, t_m = target_image.shape
factors = [ ]
grid_color_list = [ ]
if self.intersection < 0:
grid_color, grid_size, frame = find_grid(target_image)
if grid_color < 0:
return factors, [ ]
factors = [glid_size]
grid_color_list = self.sample["train"][0]["colors"][glid_color]
self.frame = frame
else:
for i in range(1, t_n, + 1):
for j in range(1, t_m + 1):
if (t_n - self.intersection) % 1 == 0 and (t_m - self.intersection) % j == 0:
factors.append([i, j])
return factors, grid_color_list
*ここで、preprocessingのfind_grid( )を見ておこう。
def find_grid(image, frame=False, possible_colors=None):
""" Looks for the grid in image and returns color and size """
grid_color = -1
size = [1, 1]
if possible_colors is None:
possible_colors = list(range(10))
for color in possible_colors:
for i in range(size[0] +1, image.shape[0] // 2 + 1):
if (image.shape[0] +1) % i == 0:
step = (image.shape[0] +1) // i
if (image[(step - 1) : : step] == color).all( ):
size[0] = i
grid_color = color
for i in range(size[1] +1, image.shape[1] // 2 + 1):
if (image.shape[1] +1) % i == 0:
step = (image.shape[1] +1) // i
if (image[(step - 1) : : step] == color).all( ):
size[1] = i
grid_color = color
preprocessing.pyのコードの簡単なものから眺めていこう。
1.
def get_rotation(image, k):
return 0, np.rot90(image, k)
kは整数で、回転角は、90 * kで、反時計回り。
2.
def get_transpose(image):
return 0, np.transpose(image)
行と列の入れ替え(転置)
3.
def get_roll(image, shift, axis)
return 0, np.roll(image, shift=shift, axis=axis)
*またまた、途中で放り出すことになってしまった。
*ARCに興味がなくなった。
*知能テストを、ヒトが解くように解くことができるプログラムを開発するという目的において、重要なことは、例題から解き方を学ぶこと。
*ARCは、どれも、例題が3つくらいある。複数の例題があってこそ、出力が一意に決まるものもあるが、1つの例題だけで済ませた方が楽しものも多く、それで出力が一意に決まるものを見つける方が楽しい。
*あえて言えば、例題はすべて1つにして、複数の正解があってもいいのではないだろうか。
*あとは、やはり、1つしかない例題から、変換方法を見つけ出すことを考えるようなプログラムを作ってみたいと思うので、そちらをやってみる。
おわり





















