I'm glad you asked! Many people come to GitHub because they want to contribute to open source📖 projects, or they're invited by teammates or classmates who use it for their projects. Why do people use GitHub for these projects?
Open source software is software that can be freely used, modified, and shared (in both modified and unmodified form) by anyone. Today the concept of "open source" is often extended beyond software, to represent a philosophy of collaboration in which working materials are made available online for anyone to fork, modify, discuss, and contribute to.
A fork is a personal copy of another user's repository that lives on your account. Forks allow you to freely make changes to a project without affecting the original upstream repository. You can also open a pull request in the upstream repository and keep your fork synced with the latest changes since both repositories are still connected.
GitHubの中に、Learnibg labというのがあり、いろいろ学べるようになっているのだが、Introduction to GitHubを最初にやりましょうと促されたので、やってみることにした。
Introduction to GitHubは、1から8までのコースステップからなっていて、このコースを完了すれば次のステップに進めるようになっているようだ。逆にいえば、このコースを完了しないと、GitHubを利用することはできないのではないかと推測される。
1から8までのステップの項目は、1. Assign yourself, 2. Turn on GitHub Pages, 3. Close an issue, 4. Create a branch, 5. Commit a file, 6. Open a pull request, 7. Respond to a review, 8. Merge your pull request, となっていて、GitHubでの操作手順の説明がなされているようである。
Despite the simplicity of the restricted Boltzman machines, very accurate results for bothground-state and dynamical properties of prototypical spin models can be readily obtained.
図のタイトルを並べてみると、
Figure 1. Artificial Neural Network encoding a many-body quantum state of N spins.
Figure 2. Neural Network representation of the many-body ground states of prototypical spin models in one and two dimensions.
Figure 3. Finding the many-body ground-state energy with neural-network quantum states.
Figure 4. Describing the many-body unitary time evolutionwith neural-network quantum states. Shown are results for the time evolution induced by a quantum quench in the microscopical parameters of the models we study (the transverse field h, for the TFI model and the coupling constant Jz in the AFH model).
TFI : transverse-field Ising (model)
AFH : anti-ferromagnetic Heisenberg (model)
11月11日(水)
HermannらのPauliNetの成果
PauliNet outperforms comparable state-of-the-art VMC anzats for atoms, diatomic molecules and a strong-correlated hydrogen chain by a margin and is yet computational efficient.
Using no data other than atomic positions and charges, we predict the dissociation curves of the nitrogen molecule and hydrogen chain, two challenging strongly correlated systems, to significantly higher accuracy than the coupled cluster method, widely considered the most accurate scalable method for quantum chemistry at equilibrium geometry.
While CCSD(T) is exceptionally accurate for equilibrium geometries,it often fails for molecules with low-lying exited states or stretched, twisted or otherwise out-of-equiliblrium geometries.
REDME.mdの最後に、This is not an officialGoogle product.と書かれていて不安になるが、アルファ碁を開発し、その後はバイオやフィジックスなどの自然科学の領域でも影響力を増しているDeepMindが運営している89のrepositoriesのうちの1つである。
PauliNetの開発者Jan Hermann氏は、量子物理の専門家であり、計算物理の専門家でもある。Hermann氏のGitHubには45のrepositoriesがあり、量子物理計算関連の内容がメインで、pySCFやSchNet(K.T. Schütt. P.-J. Kindermans, H. E. Sauceda, S. Chmiela, A. Tkatchenko, K.-R. Müller. SchNet: A continuous-filter convolutional neural network for modeling quantum interactions. Advances in Neural Information Processing Systems 30, pp. 992-1002 (2017))なども含まれている。
Most of my programming is related to my research in computational materials science. I believe that strong computational science benefits from strong software engineering, and that all scientific academic software should be open source.
Recent developments in the PySCF program package Qiming Sun et al., arXiv:2002.12531v2 [physics.chem-ph] 11 Jul 2020
abstract
PYSCF is a Python-based general-purpose electronic structure platform that both supports first-principles simulations of molecules and solids, as well as accelerates the development of new methodology and complex computational workflows.
The present paper explains the design and philosophy behind PYSCF that enables it to meet these twin objectives.
With several case studies, we show how users can easily implement their own methods using PYSCF as a development environment.
We then summarize the capabilities of PYSCF for molecular and solid-state simulations.
Finally, we describe the growing ecosystem of projects that use PYSCF across the domains of quantum chemistry, materials science, machine learning and quantum information science.
machine learningに関係する記述を次に示す。
A. PySCF in the materials genome initiative and machine learning
As discussed in section I, one of our objectives when developing PYSCF was to create a tool which could be used by non-specialist researchers in other fields.
With the integration of machine learning techniques into molecular and materials simulations, we find that PYSCF is being used in many applications in conjunction with machine learning.
For example, the flexibility of the PYSCF DFT module has allowed it to be used to test exchange-correlation functionals generated by machine-learning protocols in several projects, and has been integrated into other machine learning workflows.
PYSCF can be used as a large-scale computational engine for quantum chemistry data generation.
Also, in the context of machine learning of wavefunctions, PYSCF has been used as the starting point to develop neural network based approaches for SCF initial guesses, for the learning of HF orbitals by the DeepMind team, and for Hamiltonian integrals used by fermionic neural nets in NETKET.
最後のNETKETってなんだろう。
著者19名の論文が出ている。
トップオーサーのCarleo氏は最初に多体問題にNNを適用した2017年の論文の著者。
NetKetを共通基盤にして、さらなる発展を目指すということかな。
NetKet: A machine learning toolkit for many-body quantum systems Giuseppe Carleo, Kenny Choo et al., SoftwareX 10 (2019) 100311
abstract
We introduce NetKet, a comprehensive open source framework for the study of many-body quantum systems using machine learning techniques.
The framework is built around a general and flexible implementation of neural-network quantum states, which are used as a variational ansatz for quantum wavefunctions.
NetKet provides algorithms for several key tasks in quantum many-body physics and quantum technology, namely quantum state tomography, supervised learning from wavefunction data, and ground state searches for a wide range of customizable lattice models.
Our aim is to provide a common platform for open research and to stimulate the collaborative development of computational methods at the interface of machine learning and many-body physics.
NetKetのホームページがある。
What is NetKet?
NetKet is an open-source project delivering cutting-edge methods for the study of many-body quantum systems with artificial neural networks and machine learning techniques.
Ubuntuはメジャーではなさそうだが、Kerasを開発したF. Cholleさんが、著書Deep Learning with PythonのAppendixAに、Installing Keras and its dependences on Ubuntuという記事を書かれていたことと、12年ほど前にイオン散乱シミュレーションのソフトを使おうとしたときに、教授から渡されたソフトがUbuntu上で動いていて、Ubuntuの入門書を渡されたということがあって、自分の中ではメジャーであった。しかし、今から思えば残念なのだが、ほどなくして、Windows上で動作する高性能のシミュレーションソフトを使うことになって、Ubuntuという奇妙な単語だけが頭に残った。さらに、F. Cholle氏のテキストをバイブルとしてディープラーニングを学ぶときにはAppendixAの記事を読む前にGPUを搭載したWindowsマシンを購入してAnaconda3上でKeras/TensouFlowを使うようになっていたので、後に、Ubuntuを使ってみたいと思ったときには、時すでに遅し、大きな壁が立ちはだかっていたのである。
We introduce NetKet, a comprehensive open source framework for the study of many-body quantum systems using machine learning techniques.
The framework is built around a general and flexible implementation of neural-network quantum states, which are used as a variational ansatz for quantum wavefunctions.
NetKet provides algorithms for several key tasks in quantum many-body physics and quantum technology, namely quantum state tomography, supervised learning from wavefunction data, and ground state searches for a wide range of customizable lattice models.
Our aim is to provide a common platform for open research and to stimulate the collaborative development of computational methods at the interface of machine learning and many-body physics.
NetKitの論文を最後まで読んでみた感想:
neural-network quantum states (NQS)とrestricted Boltzman machine (RBM)が根底にあり、C++でプログラムを強化しているようである。使いやすさを強調しており、例題をみると、プログラムコードは非常に単純化されていて、確かに、すぐに使えそうな感じである。機械学習と量子化学計算の橋渡しをするプログラム開発の拠点を目指しているようである。
ここで紹介している3種類のNNは、波動関数をなんらかの方法でNNに記述し、その波動関数に物理的意味を与える(最適化する)ために、そのNNを、VMC(variational Monte Carlo)等を用いて学習させる。そうすると、学習したNNは、基底状態だけでなく、非平衡状態や励起状態の分子のエネルギーをも計算することができる、というものだと理解している。
Physical machine learning outperforms “human learning” in Quantum Chemistry A. V. Sinitskiy and V. S. Pande, Department of Bioengineering, Stanford University, Stanford CA 94305, arXiv:1908.00971 (2019).
abstract
Two types of approaches to modeling molecular systems have demonstrated high practical efficiency. Density functional theory (DFT), the most widely used quantum chemical method, is a physical approach predicting energies and electron densities of molecules.
Recently, numerous papers on machine learning (ML) of molecular properties have also been published. ML models greatly outperform DFT in terms of computational costs, and may even reach comparable accuracy, but they are missing physicality — a direct link to Quantum Physics — which limits their applicability.
Here, we propose an approach that combines the strong sides of DFT and ML, namely, physicality and low computational cost. By generalizing the famous Hohenberg-Kohn theorems, we derive general equations for exact electron densities and energies that can naturally guide applications of ML in Quantum Chemistry. Based on these equations, we build a deep neural network that can compute electron densities and energies of a wide range of organic molecules not only much faster, but also closer to exact physical values than current versions of DFT. In particular, we reached a mean absolute error in energies of molecules with up to eight non-hydrogen atoms as low as 0.9 kcal/mol relative to CCSD(T) values, noticeably lower than those of DFT (down to ~3 kcal/mol on the same set of molecules) and ML (down to ~1.5 kcal/mol) methods. A simultaneous improvement in the accuracy of predictions of electron densities and energies suggests that the proposed approach describes the physics of molecules better than DFT functionals developed by “human learning” earlier. Thus, physics-based ML offers exciting opportunities for modeling, with high-theory-level quantum chemical accuracy, of much larger molecular systems than currently possible.
Recently, many authors used machine learning (ML) for much faster computations of E and some other molecular properties (polarizabilities, HOMO-LUMO gaps, etc.).
However, neither currently used descriptors of molecules, nor ML models have a transparent connection to the basic physical concepts derived from the Schrödinger equation.
For example, the vast majority of ML models cannot be extended to compounds with new elements without retraining, making them methodologically inferior even to least accurate DFT functionals, let alone the absolutely transferable Schrödinger equation.
As a result, such approaches might be devoid of physics, and the criticism of ML as “black boxes” and “curve-fitting” seems totally applicable to them.
A. V. Sinitskiyらは、上記abstractの紫色で示したように、ネットワークの中に物理(DFT)を持ち込み、持ち込んだ関数をDNNで最適化することによってDFTよりも高性能なCCSD(T)を超える正確さでEやρを高速に計算することができるとのことである。FermiNetやPauliNetは基底状態だけでなく非平衡状態(例えば結合距離を変化させたとき)や励起状態のエネルギーを計算できる。これに対して、A. V. Sinitskiyらがこの論文で示しているのは基底状態のみであるが、本文の最後に次の記述がある。
We foresee wide-scale applications of the approach proposed here (after certain technical developments) to computer modeling of various large molecular systems, including biomolecular or artificial material systems of much practical interest, and highly accurate and fast modeling of excited states of molecules and chemical reactions involving bond breaking and formation.
ここで偶然出会ったA. V. Sinitskiy and V. S. Pandeの論文は、分子を扱っていて、他の論文をみると、生体分子とタンパク質 との相互作用を計算機シミュレーションで調べているようだ。さらに、上記論文の1つ前の論文もある。Deep Neural Network Computes Electron Densities and Energies of a Large Set of Organic Molecules Faster than Density Functional Theory (DFT), Anton V. Sinitskiy, Vijay S. Pande
ということだが、A. V. Sinitskiyらの研究は、別にフォローすることにして、ここでは、FermiNetを、とことん理解することにしよう。
PauliNetのHermann先生は、論文Deep neural network solution of the electronic Schrodinge equationの中で、次のように書いている。
The parallel work of Pfau et al. (2019) follows the same basic idea as ours, but differs in several significant aspects.
Their architecture does not encode any physical knowledge about wave functions besides the essential antisymmetry, which is compensated by a much larger number of optimized parameters.
Perhaps as a result of that, their ansatz achieves somewhat higher accuracy at the cost of being about two orders of magnitude more computationally expensive than ours.
Natural Gradient Works Efficiently in Learning Shun-ichi Amari RIKEN Frontier Research Program, Saitama 351-01, Japan
This article introduces the Riemannian structures to the parameter spaces of multilayer perceptrons, blind source separation, and blind source deconvolution by means of information geometry. The natural gradient learningmethod is then introduced and is shown to be statistically efficient. This implies that optimal online learning is as efficient as optimal batch learning when the Fisher information matrix exists. It is also suggested that natural gradient learning might be easier to get out of plateaus than conventional stochastic gradient learning.
KFACの論文:
Optimizing Neural Networks with Kronecker-factored Approximate Curvature James Martens∗ and oger Grosse† Department of Computer Science, University of Toronto
Abstract We propose an efficient method for approximating natural gradient descent in neural networks which we call Kronecker-factored Approximate Curvature (K-FAC). K-FAC is based on an efficiently invertible approximation of a neural network’s Fisher information matrix which is neither diagonal nor low-rank, and in some cases is completely non-sparse. It is derived by approximating various large blocks of the Fisher (corresponding to entire layers) as being the Kronecker product of two much smaller matrices. While only several times more expensive to compute than the plain stochastic gradient, the updates produced by K-FAC make much more progress optimizing the objective, which results in an algorithm that can be much faster than stochastic gradient descent with momentum in practice. And unlike some previously proposed approximate natural-gradient/Newton methods which use high-quality non-diagonal curvature matrices (such as Hessian-free optimization), K-FAC works very well in highly stochastic optimization regimes. This is because the cost of storing and inverting K-FAC’s approximation to the curvature matrix does not depend on the amount of data used to estimate it, which is a feature typically associated only with diagonal or low-rank approximations to the curvature matrix.
An implementation of the algorithm and experiments defined in "Ab-Initio Solution of the Many-Electron Schroedinger Equation with Deep Neural Networks", David Pfau, James S. Spencer, Alex G de G Matthews and W.M.C. Foulkes, Phys. Rev. Research 2, 033429 (2020). FermiNet is a neural network for learning the ground state wavefunctions of atoms and molecules using a variational Monte Carlo approach.
Installation
pip install -e . will install all required dependencies. This is best done inside a virtual environment.
A generative model describes how a dataset is generated, in terms of a probabilistic model. By sampling from this model, we able to able to generate new data.
As well as the practical uses of generative modeling (many of which are yet to be discovered) , there are three deeper reasons why generative modeling can be considered the key to unlocking a far more sophisticated form of artificial intelligence, that goes beyond what discriminative modeling alone can achieve.
First, purely from a theoretical point of view, we should not be content with only being able to excel at categorizing data but should also seek a more complete understanding of of how the data was generated in the first place.
Second, it is highly likely that generative modeling will be central to driving future developments in other fields of machine learning, such as reinforcement learning (the study of teaching agents to optimize a goal in an envilonment through trial and error).
Finally, if we are to truly say that we have built a machine that has acquired a form of intelligence that is comparable to a human's, generative modeling must surely be part of the solution. One of the finest example of a generative model in the natural world is the person reading this book. Take a moment to consider what an incredible generative model you are.
TabNet: Attentive Interpretable Tabular Learning Sercan O. Arık and Tomas Pfister, arXiv:1908.07442v4 [cs.LG] 14 Feb 2020
ABSTRACT We propose a novel high-performance and interpretable canonical deep tabular data learning architecture, TabNet.
TabNet uses sequential attention to choose which features to reason from at each decision step, enabling interpretability and more effcient learning as the learning capacity is used for the most salient features.
We demonstrate that TabNet outperforms other neural network and decision tree variants on a wide range of non-performance-saturated tabular datasets and yields interpretable feature attributions plus insights into the global model behavior.
Finally, for the first time to our knowledge, we demonstrate self-supervised learning for tabular data, significantly improving performance with unsupervised representation learning when unlabeled data is abundant.
Solving the Quantum Many-Body Problem with Artificial Neural Networks
G. Carleo and Matthias Troyer, arXiv: 1606.02318v1 [cond-mat.dis-nn] 7 Jun 2016
この研究に至る前夜の状況が次の総説にまとめられているようである。
THE NONEQUILIBRIUM QUANTUM MANY-BODY PROBLEM AS A PARADIGM FOR EXTREME DATA SCIENCE J. K. Freericks, B. K. Nikoli´c and O. Frieder, arXiv:1410.6121v1 [cond-mat.str-el] 22 Oct 2014
Generating big data pervades much of physics.
But some problems, which we call extreme data problems, are too large to be treated within big data science.
The nonequilibrium quantum many-body problem on a lattice is just such a problem, where the Hilbert space grows exponentially with system size and rapidly becomes too large to fit on any computer (and can be effectively thought of as an infinite-sized data set).
Nevertheless, much progress has been made with computational methods on this problem, which serve as a paradigm for how one can approach and attack extreme data problems.
In addition, viewing these physics problems from a computer-science perspective leads to new approaches that can be tried to solve them more accurately and for longer times.
We review a number of these different ideas here.
Keywords: Nonequilibrium quantum many-body problem; extreme data science.
Ab initio solution of the many-electron Schrödinger equation with deep neural networks David Pfau, James S. Spencer, Alexander G. D. G. Matthews, and W. M. C. Foulkes
TabNet: Attentive Interpretable Tabular Learning Sercan O. Arık and Tomas Phister, Google Cloud AI arXiv:1908.07442v4 [cs.LG] 14 Feb 2020
ABSTRACT We propose a novel high-performance and interpretable canonical deep tabular data learning architecture, TabNet. TabNet uses sequential attention to choose which features to reason from at each decision step, enabling interpretability and more efficient learning as the learning capacity is used for the most salient features. We demonstrate that TabNet outperforms other neural network and decision tree variants on a wide range of non-performance-saturated tabular datasets and yields interpretable feature attributions plus insights into the global model behavior. Finally, for the first time to our knowledge, we demonstrate self-supervised learning for tabular data, significantly improving performance with unsupervised representation learning when unlabeled data is abundant.
Overall, we make the following contributions in the design of our method: (1) Unlike tree-based methods, TabNet inputs raw tabular data without any feature preprocessing and is trained using gradient descent-based optimization to learn flexible representations and enable flexible integration into end-to-end learning. (2) TabNet uses sequential attention to choose which features to reason from at each decision step, enabling interpretability and better learning as the learning capacity is used for the most salient features (see Fig. 1). This feature selection is instancewise, e.g. it can be different for each input, and unlike other instance-wise feature selection methods like [6] or [61], TabNet employs a single deep learning architecture with end-to-end learning. (3) We show that the above design choices lead to two valuable properties: (1) TabNet outperforms or is on par with other tabular learning models on various datasets for classification and regression problems from different domains; and (2) TabNet enables two kinds of interpretability: local interpretability that visualizes the importance of input features and how they are combined, and global interpretability which quantifies the contribution of each input feature to the trained model. (4) Finally, we show that our canonical DNN design achieves significant performance improvements by using unsupervised pre-training to predict masked features (see Fig. 2). Our work is the first demonstration of self-supervised learning for tabular data.
When using the Sequential API or the Functional API, saving a trained Keras model is as simple as it gets:
model = keras.models.Sequential([...]) # or keras.Model([...])
model.compile([...])
model.fit([...])
model.save('my_keras_model.h5')
Keras will use the HDF5 format to save both the model's architecture (including every layer's hyperparameters) and the values of all the model parameters for every layer (e.g. connection weights and biases).
It also saves the optimizer (including its hyperparameters and any state it may have).
Track knowledge states of 1M+ students in the wild
The goal is to accurately predict how students will perform on future interactions.
If successful, it’s possible that any student with an Internet connection can enjoy the benefits of a personalized learning experience, regardless of where they live.
Tailoring education to a student's ability level is one of the many valuable things an AI tutor can do.
Your challenge in this competition is a version of that overall task; you will predict whether students are able to answer their next questions correctly.
You'll be provided with the same sorts of information a complete education app would have: that student's historic performance, the performance of other students on the same question, metadata about the question itself, and more.
You’re not too far from receiving a completion certificate!
For every course you complete on Kaggle, we’ll issue an official certificate that celebrates the progress that you’ve made in your data science and machine learning journey.
MONAI aims at supporting deep learning in medical image analysis at multiple granularities. This figure shows a typical example of the end-to-end workflow in medical deep learning area:
MONAI architecture
The design principle of MONAI is to provide flexible and light APIs for users with varying expertise.
All the core components are independent modules, which can be easily integrated into any existing PyTorch programs.
Users can leverage the workflows in MONAI to quickly set up a robust training or evaluation program for research experiments.
Rich examples and demos are provided to demonstrate the key features.
Researchers contribute implementations based on the state-of-the-art for the latest research challenges, including COVID-19 image analysis, Model Parallel, etc.
The overall architecture and modules are shown in the following figure:
This competition is challenging due to the huge dataset size. In addition, people may not be familiar with medical imaging and CT scans.
To lower the barrier to entry to this competition and to encourage more people to participate, I have converted all of the DICOM images into JPEGs (about 52GB), 256x256 pixels (standard is 512x512).
# helpful character encoding module import chardet
UTF-8 is the standard text encoding. All Python code is in UTF-8 and, ideally, all your data should be as well. It's when things aren't in UTF-8 that you run into trouble.
Try using .decode()to get the string,
then .encode() to get the bytes representation, encoded in UTF-8.
micro-cource:Data Cleaning:inconsistent data entry
The first way is to include it in the data pipeline with a function like ImageDataGenerator. The second way is to include it in the model definition by using Keras's preprocessing layers. This is the approach that we'll take. The primary advantage for us is that the image transformations will be computed on the GPU instead of the CPU, potentially speeding up training.
Using this data, how can we use features such as project category, currency, funding goal, and country to predict if a Kickstarter project will succeed?
First we'll convert the state column into a target we can use in a model. Data cleaning isn't the current focus, so we'll simplify this example by:
Dropping projects that are "live"
Counting "successful" states as outcome = 1
Combining every other state as outcome = 0
この作業に異論はない。ターゲットは、プロジェクトが成功するかどうかである。
Prep categorical variables
Now for the categorical variables -- category, currency, and country -- we'll need to convert them into integers so our model can use the data. For this we'll use scikit-learn's LabelEncoder. This assigns an integer to each value of the categorical feature.
文字情報を整数に置き換えるのだが、識別子としての意味しかないので、ここに、違和感を感じる。
2. Categorical Encodings
In this tutorial, you'll learn about count encoding, target encoding, and CatBoost encoding.・・・識別子+αの意味を持たせる方法の説明のようだ。
Count encoding replaces each categorical value with the number of times it appears in the dataset. For example, if the value "GB" occured 10 times in the country feature, then each "GB" would be replaced with the number 10.
category, currency, and countryこれらを出現頻度数に置き換えると、AUCが0.7467から0.7486に上がった。
Target encoding replaces a categorical value with the average value of the target for that value of the feature. For example, given the country value "CA", you'd calculate the average outcome for all the rows with country == 'CA', around 0.28.
Finally, we'll look at CatBoost encoding. This is similar to target encoding in that it's based on the target probablity for a given value. However with CatBoost, for each row, the target probability is calculated only from the rows before it.
Google Landmarks Dataset v2 A Large-Scale Benchmark for Instance-Level Recognition and Retrieval Tobias Weyand ∗ Andre Araujo ´∗ Bingyi Cao Jack Sim Google Research, USA {weyand,andrearaujo,bingyi,jacksim}@google.com
Unifying Deep Local and Global Features for Image Search Bingyi Cao? Andr´e Araujo? Jack Sim Google Research, USA fbingyi,andrearaujo,jacksimg@google.com
For the past 10 years, our competitions have been mostly focused on supervised machine learning. The field has grown, and we want to continue to provide the data science community cutting-edge opportunities to challenge themselves and grow their skills.
So, what’s next? Reinforcement learning is clearly a crucial piece in the next wave of data science learning. We hope that Simulation Competitions will provide the opportunity for Kagglers to practice and hone this burgeoning skill.
ということで、Kaggleのコンペは、すべて、食いつこう。
9月5日(土)
新たにコンペが立ち上がった。早速参加しよう。
Mechanisms of Action (MoA) Prediction
Can you improve the algorithm that classifies drugs based on their biological activity?
If successful, you’ll help to develop an algorithm to predict a compound’s MoA given its cellular signature, thus helping scientists advance the drug discovery process.
(1) We introduce PANNs trained on AudioSet with 1.9 million audio clips with an ontology of 527 sound classes;
(2) We investigate the trade-off between audio tagging performance and computation complexity of a wide range of PANNs;
(3) We propose a system that we call Wavegram-Logmel-CNN that achieves a mean average precision (mAP) of 0.439 on AudioSet tagging, outperforming previous state-of-the-art system with an mAP 0.392 and Google’s system with an mAP 0.314;
(4) We show that PANNs can be transferred to other audio pattern recognition tasks, outperforming several state-of-the-art systems;
(5) We have released the source code and pretrained PANN models.
9月9日開始:Hash Code Archive : Drone Delivery - Can you help the drone delivery supply chain?:これは機械学習ではなく、最適化、とのこと。最適化の課題にはまだ取り組んだことが無いので、面白いかも。サンタシリーズが最適化の課題らしい。
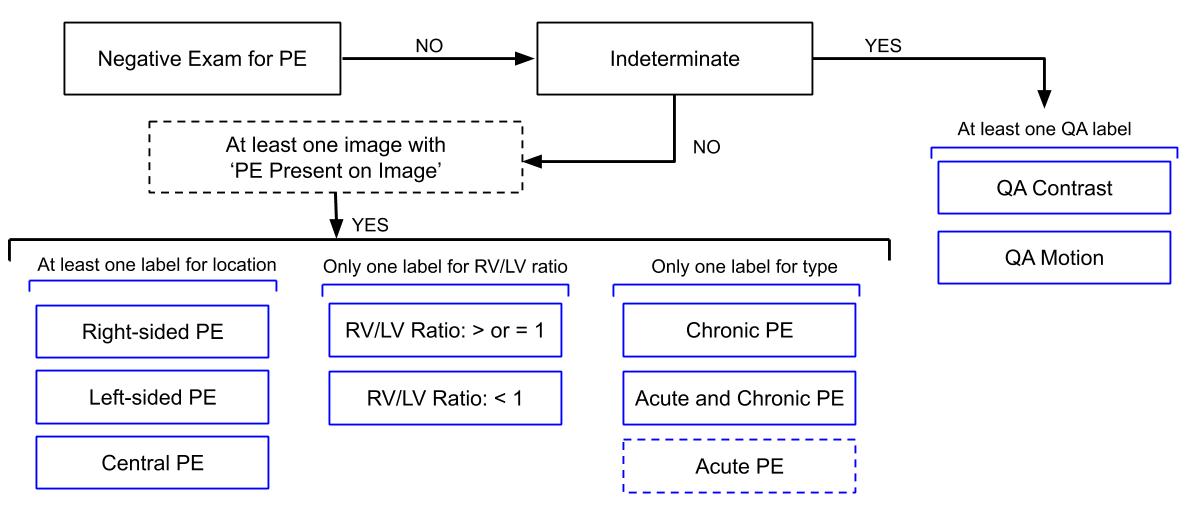
- Classify Pulmonary Embolism cases in chest CT scans -(9/10-10/27)
今回用いられているCTは、ウイキペディアによれば、以下のとおりである。
CT pulmonary angiogram (CTPA) is a medical diagnostic test that employs computed tomography (CT) angiography to obtain an image of the pulmonary arteries. Its main use is to diagnose pulmonary embolism (PE).[1] It is a preferred choice of imaging in the diagnosis of PE due to its minimally invasive nature for the patient, whose only requirement for the scan is an intravenous line.
Modern MDCT (multi-detector CT) scanners are able to deliver images of sufficient resolution within a short time period, such that CTPA has now supplanted previous methods of testing, such as direct pulmonary angiography, as the gold standard for diagnosis of pulmonary embolism.[2]
Proceedings of Machine Learning Research 101:924–939, 2019 ACML 2019 Fusing Recalibrated Features and Depthwise Separable Convolution for the Mangrove Bird Sound Classification Chongqin Lei, Weiguo Gong, and Zixu Wang
In this paper, we propose a novel method that combines the feature recalibration mechanism with depthwise separable convolution for the mangrove bird sound classification.
In the proposed method, we introduce Xception network in which depthwise separable convolution with lower parameter number and computational cost than traditional convolution can be stacked in a residual manner, as the baseline network.
And we fuse the feature recalibration mechanism into the depthwise separable convolution for actively learning the weights of the feature channels in the network layer, so that we can enhance the important features in bird sound signals to improve the performance of the classification.
In the proposed method, firstly we extract three-channel log-mel features of the bird sound signals and we introduce the mixup method to augment the extracted features.
Secondly, we construct the recalibrated feature maps including the different scales of information to get the classification results.
To verify the effectiveness of the proposed method, we build a dataset with 9282 samples including 25 kinds of the mangrove birds such as Egretta alba, Parus major, Charadrius dubius, etc. habiting in the mangroves of Fangcheng Port of China, and execute the experiments on the built dataset.
「Unifying Deep Local and Global Features for Image Search」を最初からゆっくりと読んでみよう。
1 Introduction
A global feature :
・summarizes the contents of an image
・often leading to a compact representation
・information about spatial arrangement of visual elements is lost
Local features :
・comprise descriptors and geometry information about specific image regions
・they are especially useful to match images depicting rigid objects
2 Related Work
Local features
Hand-crafted techniques such as SIFT and SURF have been widely used for retrieval problems. Early systems worked by searching for query local descriptors against a large database of local descriptors, followed by geometrically varifying database images with sufficient number of correspondencies. .......... The one most related to our work is DELF; our proposed unified model incorporates DELF's attention module, but with a much simpler training pipeline, besides also enabling global feature extraction.
TEAM JL Solution to Google Landmark Recognition 2019の記事を読んでみよう。
昨年のコンペでトップになったチームによる報告書である。
Dataset Cleaning
画像が約400万枚、約20万クラス、約5万クラスは画像が3枚以上含まれない。
前処理の詳細は、理解できない。
Global CNN Model
6種類のbackbone network、4種類のpooling operation。
Local CNN Model
Detect-to-Retrieve(D2R) : Detect-to-Retrieve: Efficient Regional Aggregation for Image Search. Marvin Teichmann, Andre Araujo, Menglong Zhu, and Jack Sim
Step-1: Global Search
Step-2: Local Search on Global Candidates
Step-3: Re-Ranking
This re-ranking step aims at distinguishing real landmark images from distrantors.
Results
Conclusion
References 15件
2位をみてみよう。
K. Chen et al., 2nd Place and 2nd Place Solution to Kaggle Landmark Recognition and Retriecal Competition 2019
引用文献21件
3位をみてみよう。
K. Ozaki and S. Yokoo, Large-scale Landmark Retrieval/Recognition under a Noisy and Diverse Dataset
“OSIC was created to bring divergent groups together to look at new ways of fighting complex lung disease,” said Elizabeth Estes, the consortium’s executive director. “In addition to utilizing expertise from academia, industry and philanthropy, we wanted to introduce clinicians to the broader artificial intelligence and machine learning community to see if new eyes and new tools could help us move forward, faster. We are excited to see the progress that can be made for patients all over the world.” OSIC is supported by a myriad of collaborative academic and industry institutions, including founding members Boehringer Ingelheim, Siemens Healthineers, CSL Behring, FLUIDDA, Galapagos, National and Kapodistrian University of Athens, Université de Lyon, Fondazione Policlinico Universitario Agostino Gemelli, and National Jewish Health. All members work in pre-competitive areas for mutual benefit and, most importantly, the benefit of patients.
I'm Something of a Painter Myself - Use GANs to create art - will you be the next Monet? に参加して、公開コードを実行していた。賞金レースではないし、メダルも出ない。教育的なコンペで、チュートリアルコードが用意されている。チュートリアルコードをチューニングしてスコアを上げるのだが、何回かやれば、頭打ちになる。次のコードを探すのだが、つわものがやってきて、ハイスコアのコードを見せてくれる。チュートリアルにはなかった、augmentationを追加しており、見事な出来栄えになっている。ベースコードに機能が追加されているので、両者を比べることによって、何をどこに配置すればよいのかがわかるので、効果を肌で感じながら、コーディング技術を学べる。
チュートリアルコードは、CycleGANを使っている。David Fosterさんの著書にGenerative Deep Learning - Teaching Machines to Paint, Write, Compose and Play - というのがある。第5章のPaintでは、CycleGANが20ページ、Neural Style Transferが10ページほど、紹介されている。自分はまだNeural Style Transferしか使ったことが無いので、これは良い機会だ。
FINDING AND FOLLOWING OF HONEYCOMBING REGIONS IN COMPUTED TOMOGRAPHY LUNG IMAGES BY DEEP LEARNING Emre EGR˘ ˙IBOZ1, Furkan KAYNAR1, Songul VARLI ¨1, Benan MUSELL ¨ ˙IM2, Tuba SELC¸ UK3
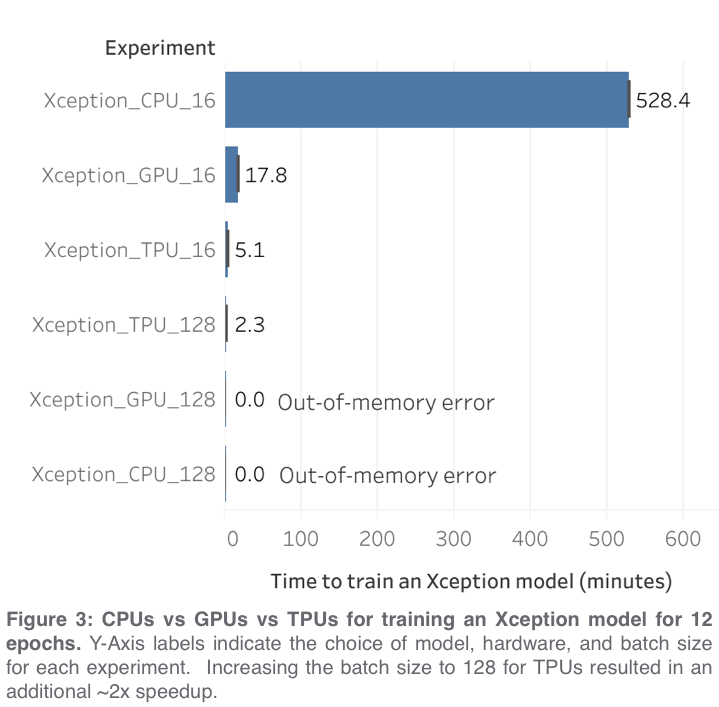
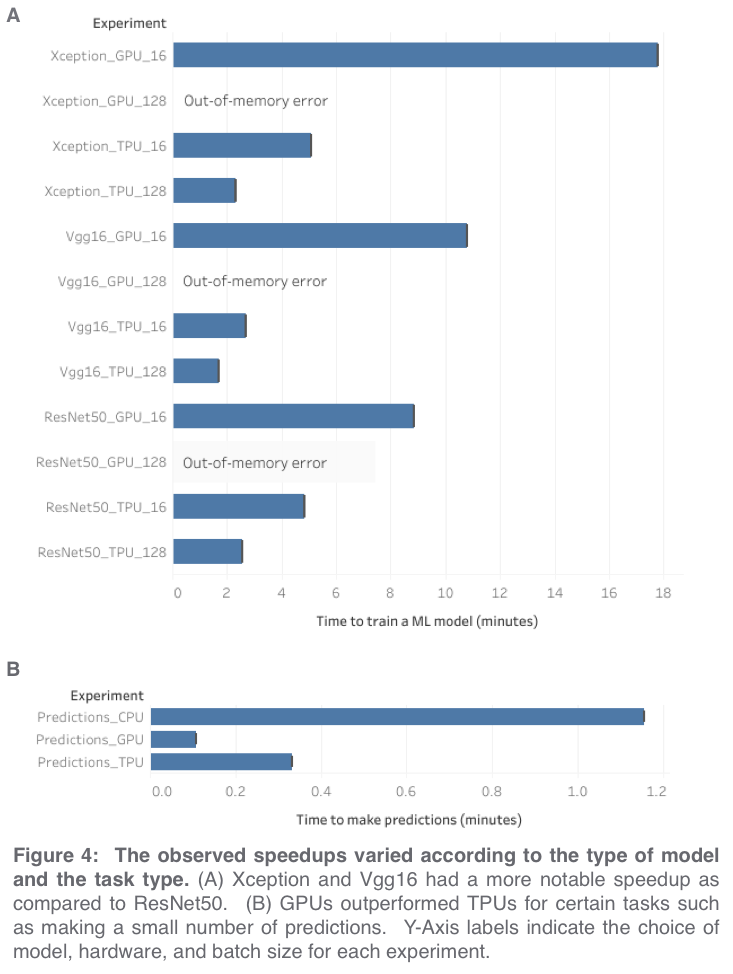
When to use CPUs vs GPUs vs TPUs in a Kaggle Competition. by Paul Mooney
In order to compare the performance of CPUs vs GPUs vs TPUs for accomplishing common data science tasks, we used the tf_flowers dataset to train a convolutional neural network, and then the exact same code was run three times using the three different backends (CPUs vs GPUs vs TPUs; GPUs were NVIDIA P100 with IntelXeon 2GHz (2 core) CPU and 13GB RAM. TPUs were TPUv3 (8 core) with IntelXeon 2GHz (4 core) CPU and 16GB RAM). The accompanying tutorial notebook demonstrates a few best practices for getting the best performance out of your TPU.
For our first experiment, we used the same code (a modified version*** of the official tutorial notebook) for all three hardware types, which required using a very small batch size of 16 in order to avoid out-of-memory errors from the CPU and GPU. Under these conditions, we observed that TPUs were responsible for a ~100x speedup as compared to CPUs and a ~3.5x speedup as compared to GPUs when training an Xception model (Figure 3). Because TPUs operate more efficiently with large batch sizes, we also tried increasing the batch size to 128 and this resulted in an additional ~2x speedup for TPUs and out-of-memory errors for GPUs and CPUs. Under these conditions, the TPU was able to train an Xception model more than 7x as fast as the GPU from the previous experiment****.