Kaggle散歩(2021年6月)
不特定コンペ
6月9日(水)
CommonLit:1,913 teams, 2 months to go
Rate the complexity of literary passages for grades 3-12 classroom use
3-12 classroomの子供たちにとって読みやすいかどうか、読みやすさの程度を推測するモデルを競うもの。機械学習において難問のように思うが、その前に、学校の教師、教育関係者、研究者にとっても評価のわかれる課題のように思う。まだ少し見ただけだが、Kagglerたちのdiscussionも白熱しているようだ。
予測モデルの一例:
https://huggingface.co/transformers/model_doc/roberta.html:
以下はこのサイトから引用
Transformers
State-of-the-art Natural Language Processing for Jax, Pytorch and TensorFlow
RoBERTa
Overview
The RoBERTa model was proposed in
RoBERTa: A Robustly Optimized BERT Pretraining Approach
by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google’s BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with much larger mini-batches and learning rates.
The abstract from the paper is the following:
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.
自然言語処理はあまりやっていないので少しずつ習得しよう。
Coleridge Initiative:1,447 teams, 14 days to go
Coleridge Initiative - Show US the Data, Discover how data is used for the public good
In this competition, you'll use natural language processing (NLP) to automate the discovery of how scientific data are referenced in publications. Utilizing the full text of scientific publications from numerous research areas gathered from CHORUS publisher members and other sources, you'll identify data sets that the publications' authors used in their work.
論文から、情報を抽出する技術?
抽出した情報の正確さや、実験結果の解釈の正確さや、式の導出の正確さなども含めて評価できれば、論文の査読システムとして、論文作成者の手助けとして、役に立つかもしれないが・・・。
これも自然言語処理なので少しずつ習得しようと思っている。
Berkeley SETI Research Center:854 teams, 2 months to go
SETI Breakthrough Listen - E.T. Signal Search
Find extraterrestrial signals in data from deep space
Search for ExtraTerrestrial Intelligence:地球外知的生命体の探索
面白そうだな。
6月10日(木)
Berkeley SETI Research Center:873 teams, 2 months to go
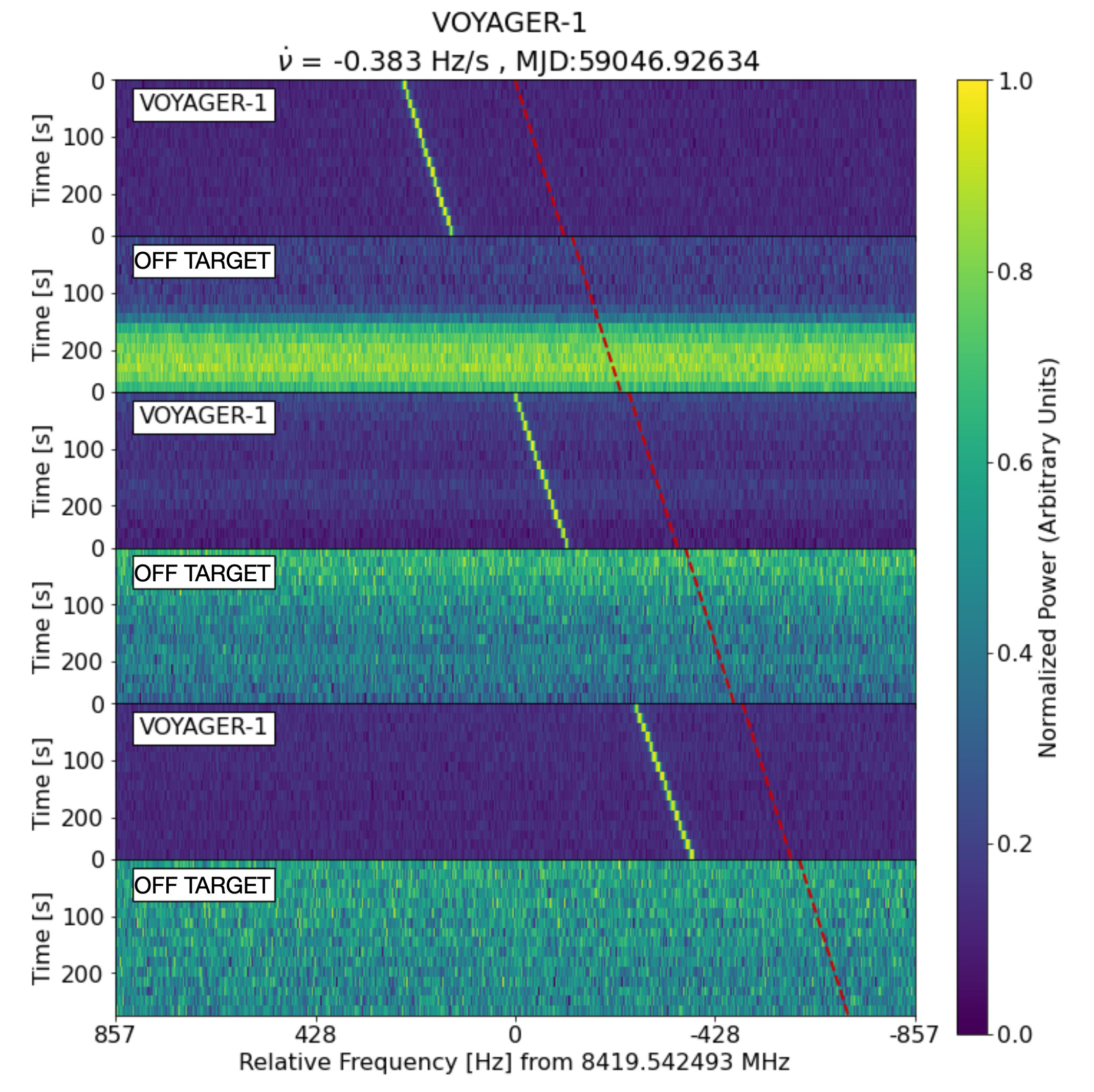
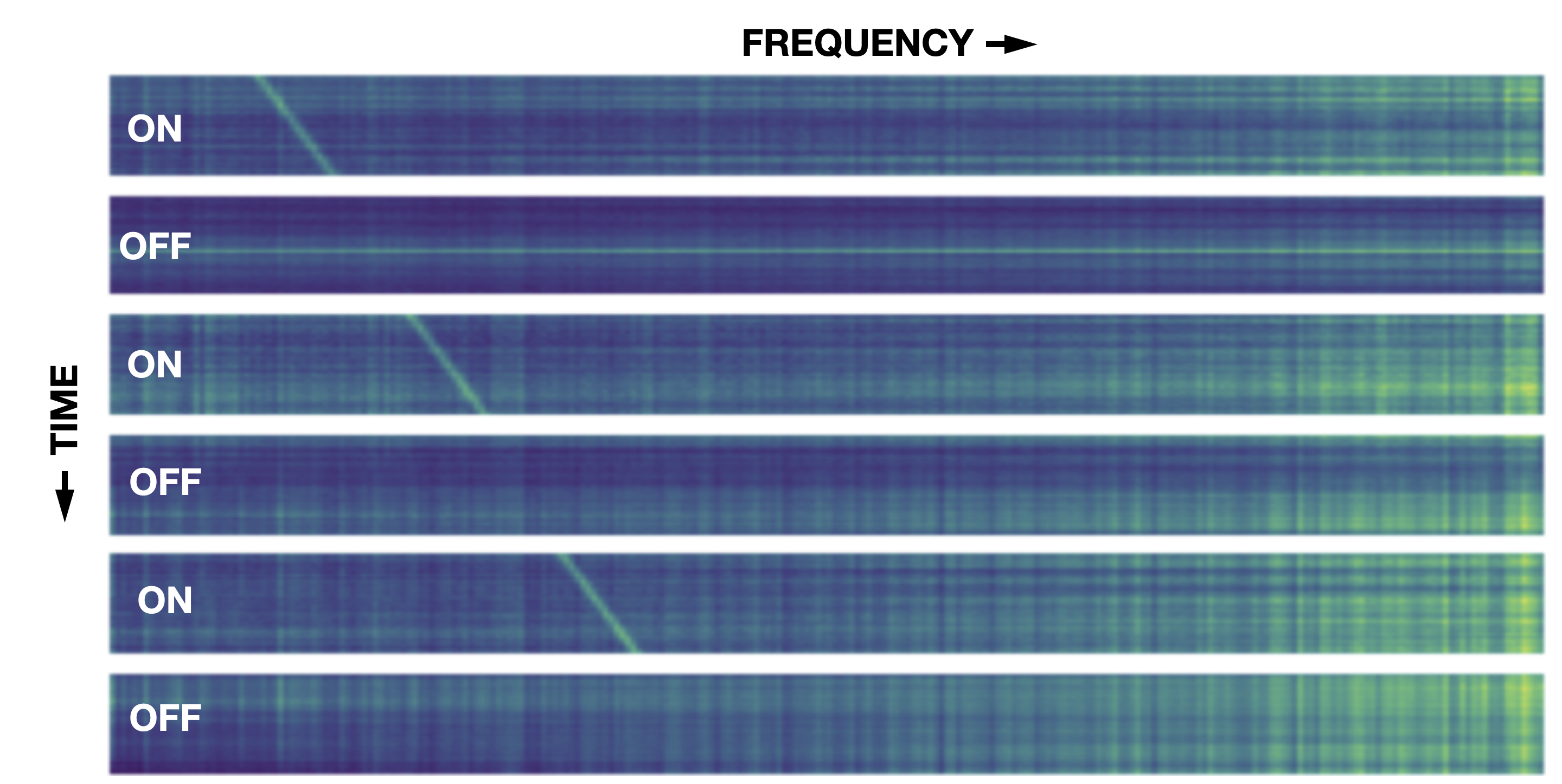
信号を受信する方向を交互に切り替えれば、特定の方向からなにがしかの信号が放出されていると推定され、その信号を発している主体を、地球外知的生命体とみなすということのようである。
上側の画像は実際にボイジャーからの信号を受け取った物で、ボイジャーの方向と外した方向からの信号を受信している。
下側の画像は、地球外知的生命体が発する信号を模擬したときに検出されるであろう信号を模擬したものである。
そんなに難しい課題ではないように思う。
Coleridge Initiative:1,478 teams, 12 days to go
公開コードをコピーして、submitした。これから、コードの内容を学んで、スコアアップにもっていきたい。
関係ないかもしれないが、Coleridge Initiativeで検索したら、こんな論文があ,った。
Harvard Data Science Review • Issue 3.2, Spring 2021
Enhancing and Accelerating Social Science Via Automation: Challenges and Opportunities
Tal Yarkoni, Dean Eckles, James A. J. Heathers, Margaret C. Levenstein, Paul E. Smaldino, Julia Lane Published on: Apr 30, 2021 DOI: 10.1162/99608f92.df2262f5
6月11日(金)
- Coleridge Initiative:
- 1,483 teams
- 12 days to go
The objective of the competition is to identify the mention of datasets within scientific publications. Your predictions will be short excerpts from the publications that appear to note a dataset.
引用していると推測される、出版物に掲載されているデータセットを特定して、短い抜粋として記述する。複数のデータセットがあれば、区切り記号を使って示す。
Transformersライブラリーに学ぶ
次のようなタスクに分けられている。文献中で使われているデータセットを抽出するにはどうすればよいのだろうか。
・Sentiment analysis: is a text positive or negative?
・Text generation (in English): provide a prompt and the model will generate what follows.
・Name entity recognition (NER): in an input sentence, label each word with the entity it represents (person, place, etc.)
・Question answering: provide the model with some context and a question, extract the answer from the context.
・Filling masked text: given a text with masked words (e.g., replaced by [MASK]), fill the blanks.
・Summarization: generate a summary of a long text.
・Translation: translate a text in another language.
・Feature extraction: return a tensor representation of the text.
要約を作ってみてそこにデータセットの情報が含まれるかどうか調べる。
データセットは何を使っていますか?と聞いて答えさせる。
質問の仕方によって答えは違ってくるかもしれないが、試してみる価値はありそう。
この文献は*****を参考にして書かれています。という文章の*****の部分の穴埋めをさせてみる。
固有表現抽出の方法(まだ理解できていないが)を使って、単語以上、文章以下の単語のクラスター(句)が表すエンティティ―のラベルを付けて、データセットに相当するものを引き出す。
dataset_titleと類似した句を抽出する。
明日は、Transformersライブラリーの学習を進めるとともに、Transformersライブラリーを使っている公開コードを探し、あれば、それに学びながら、スコアアップの方法を探っていこう。
6月12日(土)
Coleridge Initiative:1,495 teams, 11 days to go
BERTの論文:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova, Google AI Language arXiv:1810.04805v2 [cs.CL] 24 May 2019
Abstract
We introduce a new language representation model called BERT, which stands for
Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
トランスフォーマーからの双方向エンコーダー表現を表すBERTと呼ばれる新しい言語表現モデルを紹介します。 最近の言語表現モデル(Peters et al。、2018a; Radford et al。、2018)とは異なり、BERTは、すべてのレイヤーで左右両方のコンテキストを共同で調整することにより、ラベルのないテキストから深い双方向表現を事前トレーニングするように設計されています。 その結果、事前にトレーニングされたBERTモデルを1つの追加出力レイヤーで微調整して、質問応答や言語推論などの幅広いタスク用の最先端のモデルを作成できます。タスク固有のアーキテクチャを大幅に変更する必要はありません。by Googlr翻訳
A.3 Fine-tuning Procedure
For fine-tuning, most model hyperparameters are the same as in pre-training, with the exception of the batch size, learning rate, and number of training epochs. The dropout probability was always kept at 0.1. The optimal hyperparameter values are task-specific, but we found the following range of possible values to work well across all tasks:
• Batch size: 16, 32 • Learning rate (Adam): 5e-5, 3e-5, 2e-5
• Number of epochs: 2, 3, 4
このファインチューニング条件が目にとまり、かつ、ここに転載する理由は、開催中のCommonLitコンペにおいて、でtransformerモデル(model = AutoModelForSequenceClassification.from_pretrained)を用いたtrainingのハイパーパラメータが、ほぼ、この条件に合っていて、これを外すとトレーニングがうまくいかなったことがあったからである。
transformers v.4.6.0:
Sequence Classification:
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc")
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc")
Extractive Question Answering:
>>> tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
>>> model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
Language Modeling:
Language modeling is the task of fitting a model to a corpus, which can be domain specific. All popular transformer-based models are trained using a variant of language modeling, e.g. BERT with masked language modeling, GPT-2 with causal language modeling.
Language modeling can be useful outside of pretraining as well, for example to shift the model distribution to be domain-specific: using a language model trained over a very large corpus, and then fine-tuning it to a news dataset or on scientific papers e.g. LysandreJik/arxiv-nlp.
Masked Language Modeling:
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-cased")
>>> model = AutoModelWithLMHead.from_pretrained("distilbert-base-cased")
Causal Language Modeling:
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
>>> model = AutoModelWithLMHead.from_pretrained("gpt2")
Text Generation:
>>> model = AutoModelWithLMHead.from_pretrained("xlnet-base-cased")
>>> tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
Named Entity Recognition:
>>> model = AutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english")
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
Summarization:
Summarization is the task of summarizing a document or an article into a shorter text. If you would like to fine-tune a model on a summarization task, you may leverage the run_summarization.py script.
>>> model = AutoModelWithLMHead.from_pretrained("t5-base")
>>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
Translation:
Translation is the task of translating a text from one language to another. If you would like to fine-tune a model on a translation task, you may leverage the run_translation.py script.
>>> model = AutoModelWithLMHead.from_pretrained("t5-base")
>>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
>>> inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="pt")
>>> outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True)
>>> print(tokenizer.decode(outputs[0]))
Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.
ゼロからコードを書くことができればよいのだが、そうはいかないので、公開コードを探そう。なかなか良さそうなのがみつからない。
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer, Facebook AI arXiv:1910.13461v1 [cs.CL] 29 Oct 2019
BERTと間違ったのかと思ったら、BARTというのも別にあって驚いた、というくらいこの分野には疎い。
In this paper, we present BART, which pre-trains a model combining Bidirectional and Auto-Regressive Transformers. BART is a denoising autoencoder built with a sequence-to-sequence model that is applicable to a very wide range of end tasks. Pretraining has
two stages (1) text is corrupted with an arbitrary noising function, and (2) a sequence-to-sequence model is learned to reconstruct the original text. BART uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pretraining schemes (see Figure 1).
この論文では、双方向トランスフォーマーと自己回帰トランスフォーマーを組み合わせたモデルを事前トレーニングするBARTを紹介します。 BARTは、シーケンス間モデルで構築されたノイズ除去オートエンコーダです。
非常に幅広いエンドタスクに適用できます。 事前トレーニングには2つの段階があります(1)テキストは任意のノイズ処理機能で破損し、(2)シーケンス間モデルは元のテキストを再構築するために学習されます。 BARTは、標準のTranformerベースのニューラル機械翻訳アーキテクチャを使用します。これは、その単純さにもかかわらず、BERT(双方向エンコーダーによる)、GPT(左から右へのデコーダーを使用)、およびその他の多くの最近の事前トレーニングスキームを一般化したものと見なすことができます。 (図1を参照)by Google翻訳

とりあえず、こんな感じ。 GPT --> BERT --> BART
6月13日(日)
CommonLit:2,031 teams, 2 months to go
CommonLiコンペはテキストの一節からテキストの読みやすさを数値化する(3学年から12学年の範囲内に該当するか否かをRMSE値で評価する)。
モデルはbert, roberta-base, roberta-largeなど。overfittしやすく、最適エポック数は少ない。エポック数では調節しずらく、ステップ数で評価している人もいるようだ。
現時点では公開コードを借用すれば銀~銅メダル圏内だが、現状の公開コードをそのまま使っただけでは、8月2日の最終日までには、追い出されているだろうな。それまでに、公開コードに学んでスコアアップの手段を探さないとだめだろうな。
Coleridge Initiative:1,514 teams, 10 days to go
今見ている公開コードにliteral matchingという項目がある。単純に、文字合わせ、ということだろうか。
6月14日(月)
Google:443 teams, 2 months to go
Google Smartphone Decimeter Challenge
Improve high precision GNSS positioning and navigation accuracy on smartphones
Global Navigation Satellite System (GNSS) provides raw signals, which the GPS chipset uses to compute a position. Current mobile phones only offer 3-5 meters of positioning accuracy. While useful in many cases, it can create a “jumpy” experience. For many use cases the results are not fine nor stable enough to be reliable.
グローバルナビゲーション衛星システム(GNSS)は、GPSチップセットが位置を計算するために使用する生の信号を提供します。 現在の携帯電話は、3〜5メートルの測位精度しか提供していません。 多くの場合便利ですが、「ジャンピー」な体験を生み出すことができます。 多くのユースケースでは、結果は良好ではなく、信頼できるほど安定していません。by Google翻訳
In this competition, you'll use data collected from the host team’s own Android phones to compute location down to decimeter or even centimeter resolution, if possible. You'll have access to precise ground truth, raw GPS measurements, and assistance data from nearby GPS stations, in order to train and test your submissions.
このコンテストでは、ホストチームのAndroidスマートフォンから収集したデータを使用して、可能であればデシメートルまたはセンチメートルの解像度まで位置を計算します。 提出物をトレーニングおよびテストするために、正確なグラウンドトゥルース、生のGPS測定値、および近くのGPSステーションからの支援データにアクセスできます。by Google翻訳
Fast Kalman filters in Python leveraging single-instruction multiple-data vectorization. That is, running n similar Kalman filters on n independent series of observations. Not to be confused with SIMD processor instructions.
カルマンフィルターは、 離散的な誤差のある観測から、時々刻々と時間変化する量(例えばある物体の位置と速度)を推定するために用いられる。レーダーやコンピュータビジョンなど、工学分野で広く用いられる。例えば、カーナビゲーションでは、機器内蔵の加速度計や人工衛星からの誤差のある情報を統合して、時々刻々変化する自動車の位置を推定するのに応用されている。カルマンフィルターは、目標物の時間変化を支配する法則を活用して、目標物の位置を現在(フィルター)、未来(予測)、過去(内挿あるいは平滑化)に推定することができる。by Wikipedia
内容を理解するために、何日もかかりそう。
TPU仕様の公開コードを借りて、計算してみた。公開コードのスコアはLB=6.752なので、そのまま走らせて、同程度のスコアになることを確認した。
次に、GPUで走らせてみた。TensorFlow/Kerasで書かれているので、TPUを指定するコードは少なく、容易に変更できる。しかし、スピードが違う。TPU前提なので5 Foldで、エポック数が最大100に設定されている。とてもでないがGPUでは無理。と思ってテストのつもりで3エポックに設定してみたら、LB=0.676になった。それではと、6エポックに増やしたら、NNの学習は進んだはずなのだが、LB=0.701となってしまった。コードを理解しながら前進しよう。
6月15日(火)
Berkeley SETI Research Center:942 teams, a month to go
Image Size vs Scoreというタイトルで情報のやりとりが行われている。画像解像度が高いほどスコアは高い傾向にある。コードコンペではないので、使える計算資源による差が現れやすい。What's your best single model?ここでも画像サイズが話題になり、大きな画像で良いスコアだが、Kaggle kernelでは動かないという話。最後には、アンサンブルの話。
Coleridge Initiative:1,521 teams, 7 days to go
このコンテストでは、自然言語処理(NLP)を使用して、出版物で科学データがどのように参照されているかを自動的に検出します。CHORUS出版社のメンバーやその他の情報源から収集された多数の研究分野からの科学出版物の全文を利用して、出版物の著者が彼らの仕事で使用したデータセットを特定します。by Google翻訳
1対の、train_dataの全文に目を通して、train_labelがどこに、どのように書かれているかを調べてみた。
test_dataを読んで、公開コードの推測結果が、求めているデータセットに該当するかどうか調べてみた。ANDIはデータセットではないように思う。BERT-MLMによる推測結果は、Lothian Birth Cohort Studyで、研究成果ではあるがデータセットと呼べるようなものでもなさそうだ。難しい。
6月16日(水)
Major League Baseball:148 teams, 2 months to go
MLB Player Digital Engagement Forecasting
Predict fan engagement with baseball player digital content
engagementが何を意味しているのかが、わからない。
In this competition, you’ll predict how fans engage with MLB players’ digital content on a daily basis for a future date range. You’ll have access to player performance data, social media data, and team factors like market size. Successful models will provide new insights into what signals most strongly correlate with and influence engagement.
このコンテストでは、ファンがMLBプレーヤーのデジタルコンテンツを将来の日付範囲で毎日どのように利用するかを予測します。 プレーヤーのパフォーマンスデータ、ソーシャルメディアデータ、市場規模などのチーム要因にアクセスできます。 成功したモデルは、どのシグナルがエンゲージメントと最も強く相関し、影響を与えるかについての新しい洞察を提供します。by Google翻訳
engage, engagementの意味がよくわからない。
6月17日(木)
Google Smartphone Decimeter Challenge:474 teams, 2 months to go
Our team is currently using only post processing to improve the accuracy. We have found that the order of post processing changes the accuracy significantly, so we share the results.
ポストプロセスに関する手順と効果に関するDiscussionが行われている。
6月18日(金)
Berkeley SETI Research Center:1,001 teams, a month to go
There are just a few of us data scientists at Kaggle launching about 50 competitions a year with many different data types over a very wide range of domains. Worrying about leakage and other failure points keeps us up at night. We absolutely value our community's time and effort and know how important it is to have fun and challenging competitions.
残念なことに、リークがあったようだ。 Kaggle staffは、このようなトラブルが生じないように少ないメンバーで日夜頑張っておられるのだ!
もうすぐ消されると思うが、LBには、1.000が45件、0.999が75件ほど並んでいる。タイミングが合えば、自分もそこに並ぼうとしただろうな。残念なことだが。
いち早くリークに気付いて公開し、Kaggleスタッフと協力して原因究明にあたろうとするKagglerたちがいる。こういう人たちがKaggleを支えているのだろう。
6月19日(土)
Major League Baseball:194 teams, a month to go
このコンペは通常のコンペとはかなり異なるように思う。それが顕著に分かるのは、Timelineである。Training TimelineとEvaluation Timelineに分かれている。
Training Timelineにおいては、Final Submission Deadlineの約1.5週間前に、Training Setが更新されるということが書かれている。
Evaluation Timelineにおいては、以下の説明がされている。
最終提出期限後から、このコンテストの評価期間の将来の日付範囲を反映するためにリーダーボードが定期的に更新されます。その時点で、各チームが選択したノートブックがその将来のデータで再実行されます(9月15日にコンテストが終了)。これらの再実行には、2021年7月31日までに更新されたトレーニングデータが含まれます。by Google翻訳
以上のように、7月20前後にTraining Setが更新され、提出締切後には更新データによるスコアの逐次変化が9月15日まで続くので、現時点におけるスコアには、ほとんど意味が無さそうだということになる。
6月20日(日)
Major League Baseball:228 teams, a month to go
As this competition is brought to you in collaboration with the launch of Vertex AI, we're providing GCP coupons for users to try out some of the great, powerful new resources made available through Vertex AI. This includes JupyterLab Notebooks, Explainable AI, hyperparameter tuning through Vizier, and countless other AI training and deployment tools.
このコンテストはVertexAIのリリースと共同で開催されるため、ユーザーがVertexAIを通じて利用できる優れた強力な新しいリソースのいくつかを試すためのGCPクーポンを提供しています。 これには、JupyterLab Notebooks、Explainable AI、Vizierによるハイパーパラメータ調整、およびその他の無数のAIトレーニングおよび展開ツールが含まれます。by Google翻訳
Vertex AI
Vertex AI brings AutoML and AI Platform together into a unified API, client library, and user interface. AutoML allows you to train models on image, tabular, text, and video datasets without writing code, while training in AI Platform lets you run custom training code. With Vertex AI, both AutoML training and custom training are available options. Whichever option you choose for training, you can save models, deploy models and request predictions with Vertex AI.
Vertex AIは、AutoMLとAIプラットフォームを統合されたAPI、クライアントライブラリ、およびユーザーインターフェイスに統合します。 AutoMLを使用すると、コードを記述せずに画像、表、テキスト、およびビデオのデータセットでモデルをトレーニングできます。AIプラットフォームでのトレーニングでは、カスタムトレーニングコードを実行できます。 Vertex AIでは、AutoMLトレーニングとカスタムトレーニングの両方が利用可能なオプションです。 トレーニングにどのオプションを選択しても、Vertex AIを使用してモデルを保存し、モデルをデプロイし、予測をリクエストできます。by Google翻訳
JupyterLab is a next-generation web-based user interface for Project Jupyter.
Notebooks enables you to create and manage virtual machine (VM) instances that are pre-packaged with JupyterLab.
Notebooks instances have a pre-installed suite of deep learning packages, including support for the TensorFlow and PyTorch frameworks. You can configure either CPU-only or GPU-enabled instances, to best suit your needs.
Your Notebooks instances are protected by Google Cloud authentication and authorization, and are available using a Notebooks instance URL. Notebooks instances also integrate with GitHub so that you can easily sync your notebook with a GitHub repository.
Notebooks saves you the difficulty of creating and configuring a Deep Learning virtual machine by providing verified, optimized, and tested images for your chosen framework.
Introduction to Vertex Explainable AI for Vertex AI
6月23日(水)
Coleridge Initiative:1,610 teams, 5 hours ago
今朝終了した。暫定420位であった。投稿したモデルの中には、170-177位相当のものもあったが、そのモデルは、public_LBが良くなかったことと、そのモデルの計算方法が他のモデルよりも良いと判断することができず、最終投稿の2件に選ぶことができなかった。161位以内がメダル圏内だったので惜しかったと思うが、そのモデルの詳細が理解できず、private_LBが少し良かったのは偶然にすぎない。夜中(早朝)に、新たにデータセットを追加して計算したものは、データセットに過剰適合して、全滅だった。憶測にすぎないが、特定のデータセットを用いた場合に、public_LBスコアが非常に高くなることを誰かが見つけたことによって、自分を含め、多くのチームが、自然言語処理本来の機能よりも、データセットへの適合に注意が向きすぎたのではなかろうか。
6月24日(木)
CommonLit:2,402 teams, a month to go
チューニングのみ。
Google:519 teams, a month to go
チューニングのみ。
*チューニングのみでは、進歩しない。Discussionで、次のようなアドバイスをしている人がいた。公開コードのコピーは大いにやればよい。ただし、単にコピーして実行し、投稿するのではなく、自分の力量に合ったモデルを探し、そこからモデルのレベルアップを図りながらスコアアップしていくのが望ましい。
6月25日(金)
CommonLit:2,451 teams, a month to go (チューニングで50位)
Discussion:Readability(読みやすさ)とは何かを問うている。
まずは、Discussionを読まずに、自分の頭にあることを引き出してみよう。読みやすい文章は、わかりやすい文章である。わかりやすい文章は、易しい単語を使っている。わかりやすい文章は短い。わかりやすい文章は構文が簡単である。わかりやすい文章は単純である。わかりやすい文章は主語と述語を含んでいる。わかりやすい文章は論理が単純である。わかりやすい文章は具体的である。わかりやすい文章は理解しやすい。わかりやすい文章は直接的である。読みやすい。わかりやすい。理解しやすい。単純である。論理的である。論理が単純である。読みやすい文章は、知っている言葉、事柄、だけを含んでいる。学習した事、知っている事、覚えている事について書かれている。
Discussionを読んでみよう。困ったことに、英語は自分にとってreadabilityが悪い。英語であることが問題なのではなく、readabilityの評価法や評価方法の課題や問題点に関する知識が少ないために理解できないか理解するのに時間がかかるのだ。文章が表現している事柄に関する知識が無いと読めない。domain knowledgeというのかな、領域知識が必要なのだが、今は、WikipediaやGoogle Scholarがあるので便利になった。読みやすい文章は、domain knowledgeを含まず、general knowledgeだけを含む文章ということで良いのか。general knowledgeにも、レベルがある。ここで問われているのは、これ、すなわち、general knowledgeのレベルを判定することになるのかもしれない。Wikipediaを見ると、common knowledgeと混同しないようにとの注意書きがある。domain knowledgeとgeneral knowledgeとcommon knowledgeは互いに重なっている部分があるように思う。Discussionとは違うところに来てしまった。
Discussionに戻る。readabilityは、これまで蓄積されたdomain knowledgeによって定義され、評価尺度も決められている。今は、train_dataをモデルに学ばせて、忠実に再現することが求められているだけ。期待は、分散を小さくし、readabilityの評価精度を上げることだろうと思うが、そんなことしてもスコアは上がらないだろうと思う。train_dataセットが全て!だろうと思う。本当に求めているのはそこではないが、今は、幻想でしかない。
100年先の世界から振り返れば、2021年も、toy problemに四苦八苦していた時代ということになるのだろう。それとも、ヒトが優れた知能を有していると思っていること自体が幻想であって、ヒトがやっていること(知的活動であると思っていること)は、ANNによって、すでに、忠実に再現されているだけでなく、ANNは、ヒトのレベルを超えようとしているのかもしれない。100年先、1000年先の人類は何を達成し、何を求めているだろうか。
6月29日(火)
Optiver:31 teams, 3 months to go
Optiver Realized Volatility Prediction
Apply your data science skills to make financial markets better
概要(自動翻訳)
この競争の最初の3か月で、さまざまなセクターにわたる数百の株式の短期的なボラティリティを予測するモデルを構築します。数億行の非常に詳細な財務データをすぐに利用できるようになり、10分間のボラティリティを予測するモデルを設計できます。モデルは、トレーニング後3か月の評価期間に収集された実際の市場データに対して評価されます。
Volatility(自動翻訳)
ボラティリティは、あらゆるトレーディングフロアで耳にする最も顕著な用語の1つであり、それには正当な理由があります。金融市場では、ボラティリティが価格の変動量を捉えます。ボラティリティが高いと、市場が混乱し、価格が大きく変動します。ボラティリティが低いと、市場はより穏やかで静かになります。オプティバーのようなトレーディング会社にとって、ボラティリティを正確に予測することは、オプションの取引に不可欠です。オプションの価格は、原商品のボラティリティに直接関係しています。
金融関係のコンペは敬遠していたが、参加しなければ何も得られず、参加すれば、domain knlowledge、train_data、予測モデルなどの概略に関する知識を得る機会が増えるので、散歩コースに加えることにした。
XGBRegressorを使った公開コードを使ってみた。
lightgbm.LGBMRegressorを使ってみようかな。
6月30日(水)
Optiver:147 teams, 3 months to go
まだ始まったばかり。参加チーム数は147と少ないので、50位以内に入った!
XGBをLGBMに変えてスコアは良くなったが、偶然にすぎないと思っている。これから、課題に合わせてチューニングしようと思う。
generalizeが重要な課題、specializeが重要な課題、accuracyが重要な課題、・・・
これらが混ざり合っていて、その寄与率は、課題によって異なる。
画像診断の多くは、異常を見逃さないことが重要であることから、真剣に取り組む気になるが、課題によっては、真剣に取り組むのが馬鹿らしく思えてくるようなものもある。スコアを争っていると、本来の目的を忘れてしまうことがある。やりがいを感じて取り組んでいても、スコアが上がらないと興味を失うことがある。どうでもいいテーマでも、スコアが上がると、必死に取り組んで、時間を忘れることがある。ゲームに夢中になっている子供みたいに。Kaggle病にかかってしまったかな。
