機械学習は、どう使うのか、どう使われているのかを、日々、考え、調べ、学んでいる(つもりである)。
機械学習はさまざまな分野で用いられているが、機械学習を用いることによって得られた成果は、高解像度、高速、自動化、高精度化、分類、などでAI/AGIというほどのものではなく、見慣れてしまっているものが多い。
しかしながら、PauliNet, FermiNet, AlphaZero, AlphaFoldなどは、レベルが違っているように感じる。その仕組みを理解し、そのアルゴリズムを使ってみたいと思う。さらに、N. Artrithらがナノ粒子表面のDFTシミュレーションを機械学習を使って精密化している研究成果なども、実際に使ってみたいと思っている。
一昨日から、Using AI to accelerate scientific discovery - Demis Hassabis (Crick Insight Lecture Series)、のビデオを聴講している。
AlphaFoldは”32 component algorithms and 60 pages of SI”と説明されている(SI:supplemental information)。約20名が5年間をかけて開発しており、domain knowledgeを用いているので、AGIではないと述べている。
どのようなものなのか、論文をみてみよう。
Highly accurate protein structure prediction with AlphaFold
John Jumper et al., Nature, Vol 596, (2021) 583
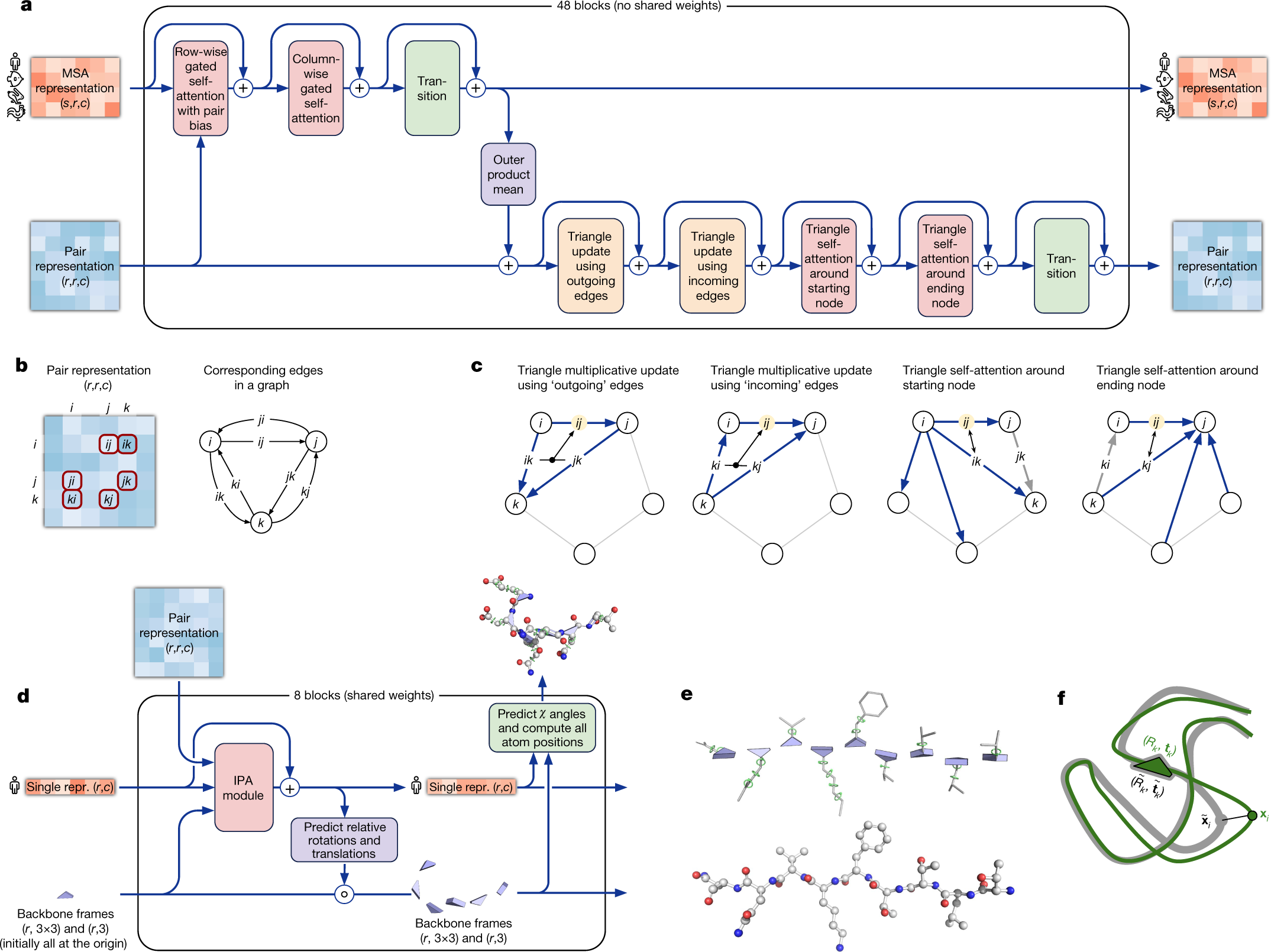

Training with labelled and unlabelled data
The AlphaFold architecture is able to train to high accuracy using only supervised learning on PDB data, but we are able to enhance accuracy (Fig. 4a) using an approach similar to noisy student self-distillation35. In this procedure, we use a trained network to predict the structure of around 350,000 diverse sequences from Uniclust3036 and make a new dataset of predicted structures filtered to a high-confidence subset. We then train the same architecture again from scratch using a mixture of PDB data and this new dataset of predicted structures as the training data, in which the various training data augmentations such as cropping and MSA subsampling make it challenging for the network to recapitulate the previously predicted structures. This self-distillation procedure makes effective use of the unlabelled sequence data and considerably improves the accuracy of the resulting network. Additionally, we randomly mask out or mutate individual residues within the MSA and have a Bidirectional Encoder Representations from Transformers (BERT)-style37 objective to predict the masked elements of the MSA sequences. This objective encourages the network to learn to
interpret phylogenetic and covariation relationships without hardcoding a particular correlation statistic into the features. The BERT objective is trained jointly with the normal PDB structure loss on the same training examples and is not pre-trained, in contrast to recent independent work.
良質な3次元構造データベースPDB(Protein Data Bank)が存在するということが大前提だということだろう。
Kaggleコンペが面白いのは、様々な分野から良質なデータベースが提供されるからだろうと思う。
プログラミング技術を習得して、Kaggleマスターを目指そう!
とは思うのだが、今は時間が取れず、Kaggleから遠ざかっている。
こんなことではだめだ。
こういうときに自分の性能を向上させるAIモデルを開発してみたいものだ。
自分の性能を向上させるAIモデルの仕様を決めよう。
Q&Aモデルが良さそうだ。
Q:現在の仕事のレベルアップとKaggleグランドマスターの両方を1年間で達成するにはどうすればよいのか。
A:現在の仕事のレベルアップに必要なAIモデルと、KaggleのGold Medalを獲得できるAIモデルを半年くらいのうちに開発すればよい。
ということで、今から実行に移そう。
