Kggle散歩(December 2020)
MoAが終了した。
現在参加しているものはいくつかあるが、今月は、Riiid!に注力しようと思う。
MoAで2つめのメダルがとれそうである(暫定181位で銀):12月11日確定!!:Kaggle Competition Expertになった。
次のランクアップのためには、金メダルが必要になる(銀も必要)。これまでの参加経験からして、相転移しなければ、金メダル獲得は無理である。金の難しさは桁違いだ。
12月1日(火)
Riiid!:2,177 teams, a month to go
the starter notebookを学習中
MoA: 終了
終了後に上位陣のスコアを生み出したコードのアーキテクチャが明らかになるので、しっかり学びたい。コンペ終了時にはいつもそう思うのだが、上っ面を眺めただけで終わってしまうことが多い。コンペが途切れた時に時間ができて過去のコンペに戻って復習しようとしても、反省すべきことも、コンペの課題もぼやけてしまっていて、結局のところ、真剣に振り返って学んだことはほとんどない。
まだ記憶に残っているうちに、次のレベルに向かうために必要なことを検討しよう。
学習を効果的に行うために必要なことは何か。Riiid!コンペの本質もそこにあると思うのだが、いつ何をどのように学習すると成績が向上するのか。なぜ、同じだけ得点をアップするのに3か月で済む人と半年以上かかる人がいるのかを考えてみる必要がある。
Riiid!が、学習の効率を測るために、学校での学習や塾での学習ではなく、TOEICを取り上げたのは、本当の理由は知らないが、次のように推測される。
TOEICには、固定した学習プログラムがなく、同じテキストと教材を使っても、スケジュールが個人任せになっているので、参加者の取り組み方に、非常に大きなばらつきが存在する可能性が高い。効果的に学習出来て成績が短期間で向上する人から、そうでない人まで、非常に広範囲にわたるデータが集まる可能性がある。学校のプログラムで同じことをやると、記憶力とか理解力が大きく反映されて、学習効率を測ることが難しくなるのではないだろうか。
本題に戻ろう。
1.現状分析
これまでに20件近くのコンペに参加した。そのうちの13件は成績が残っており、そのうちの2件は、ほんの少しだけの参加で、残りの11件は、メダル獲得を目指したものであり、入賞はLandmarkとMoA (暫定)の2件である。
まず、見えていない部分(約20件と13件の差、約7件)について検討してみよう。
記憶に新しいものはARCコンペである。これに取り組んでいた頃は、ARCの論文を勉強していて、知能テストについてもいろいろと調べていた。コンペが始まってすぐに感じたことは、コンペの主催者(F. Chollet氏)が求めていることと、現に存在している機械学習(ディープラーニング等を含む)でできることとのギャップの大きさである。このコンペは、目指しているものが非常に高いところにあるということでは歴史に残るものかもしれない。勝者はいわゆる力づくで解いたヒトのようである。train dataからできるだけ多くのパターンを把握し、test dataの例題から解答パターン(モザイクの構造パターン)を推測し、用意しておいたパターン変換を行うというもので、従来型のプログラミング手法によるものである。機械学習を用いて、興味深い結果を得ているものもいくつかあった。自分は、コンピュータに解き方を教えるための方法を考えるために、課題を解きながら解き方を分類してプログラムコードに置き換えようとしていたが、途中で投げ出してしまった。5月27日にコンペが終了した後、ARCコンペから何かを学ぼうとしたが、人工知能に関する論文(教育心理学?哲学?)をいくつか読んで終わった。
他に、かなり力を入れて参加したのは、眼底写真から病状を分類するAPTOS2019と鋼板表面の異常部を検出するSeverstalがある。
APTOS2019は、submit後にエラーになって記録が残らなかった。前処理とsubmissionファイルを作成する部分がよくわからずその部分のコードを公開コードから借用した。
Severstalは、前処理からできるようにしたいと思って、ゼロからプログラムしていたが、結局、前処理を完成することなく終わった。
このころの目標は、自前のプログラムコードを作成して、予測して、結果をsubmitして,リーダーボードに載ることだった。
ここからは、あまり見られたくないことも、少し書いておく。
Kaggleでは、まず、参加することによって得るものがあると思ったコンペに参加する。
次に、コンペの概要、データの概要をある程度把握したら、notebookのEDAをざっと見てデータの概要を図や表から、もう少し詳しく把握する。
その次に、高いスコアを得ているコードの中から、読みやすく、再チューニングやモデルの変更がしやすそうなコードをフォークして、Kaggle kernel内で実行、commit、submitする。
その次に、予測モデルのハイパーパラメータや構造をチェックして、経験上、変更した方が良さそうなパラメータ(モデルの簡単な構造変更を含む)を変更し、Kaggle kernel内で実行し、commit、submitする。
選んだモデルで得られるスコアに限界を感じたら、ディスカッションを読み、高得点を得ている公開コードをチェックする。このとき、高得点を得ていなくても、良いモデルを使っていて、読みやすい、変更しやすい、改善すべきポイントがなんとなく見える、というような公開コードを探す。
勝負は、generalizationにあり、ということで、最終段階はどのようにしてアンサンブルを行うか、ということになる。ここでは、モデルを組み合わせる技術、コンペ毎に定められている計算時間内に計算を終わらせる技術などが求められるが、これについては、まだまだ、不十分である。
2.課題と対策
グランドマスターの方々の講演を聞いていると、あるいは聞くまでもないことだが(すでに常識となっている)、データサイエンス、機械学習で最も重要なことは、データの前処理である。前処理と言っても、予測モデルに読み込ませるだけの定型的なプログラミング技術ではない。データが持っている有用な情報をいかにして取り出すかということである。雑音を除去し、重要な特徴量を抽出するだけではなく、データの中に潜んでいる、原理や法則、関係性を把握して、それをモデルに反映させることができるようにすることが重要であろう。
自分の今の課題は、1)前処理の部分を読み飛ばしていること、2)モデルの性能を左右するツールに関する勉強不足、3)後処理(submission.txtの作成を含む)の部分を読み飛ばしていること、4)チューニングに膨大な時間を費やしていること、および、5)上に書いたような前処理技術、と思っている。
これらに対する対策は、一言でいえば、当該コンペサイトのKagglerに学ぶ、ということである。できることから書いていくと、1)技術的ディスカッションの理解に努める(Discussionもしくは公開コードの後ろのComments)、2)公開コードをスコアの高いものだけ見るのではなく、自分の現状に見合ったコードやEDA中心のコードの理解に努めること、3)予測モデルの制御部分のコードを意識して理解すること、4)前処理技術を理解すること、5)後処理技術を理解すること、6)チューニングよりもコードの理解を優先すること、などである。
以上、実行あるのみ。
12月2日(水)
Riiid! Answer Correctness Prediction
NotebooksのMost Votesの最初から見ていくことにしよう。
最初は、大きなデータの扱い方で、大きなデータをpandasで普通に読み込むと、メモリーオーバーや読み込むのに10分くらいかかるところを、メモリーオーバーを生じさせることなく1分もかからず読み込む方法が紹介されている。フォーマット変換方法も紹介されていて非常に応用範囲の広いものである。
2番目は、EDA+Baselineである。図表を駆使しながら非常に丁寧に説明されている。
これまで、EDAは、ただ眺めるだけであったが、今回は、Kaggle kernel内で実行しながら学ぶことにした。そうすると、よくできたEDAは、詳細な説明とプログラムコードが交互に現れ、説明を読みながらコードセルを1つ1つ実行させていくことになるので、データの内容を調べながら、プログラムの書き方も学ぶことができる。
この調子で、チューニングのエキスパートではなく、データサイエンスと機械学習のエキスパートを目指して頑張ってみることにしよう。
12月3日(木)
Riiid! Answer Correctness Prediction
EDA + Baselineを最後まで見た。ようやく全体像が見えてきたように思う。
Baselineは、LightGBMである。
Riiid! AI Researchが、関連論文を公開している。
Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing
SAINT+: Integrating Temporal Features for EdNet Correctness Prediction
コンペと同じ条件かどうかはわからないが、AUCの最大値が0.7914となっている。
コンペでは、すでに、8チームが0.800を超えている。さすが、Kagglerってとこかな。
この、Riiid! AI Researchの論文とKagglerのスコアを見ると、このコンペでの金は無理だなと思うが、どのコンペであっても、似たようなものだろうな。APTOS2019でもコンペ開催時期に非常に優れた論文が発表されたが、Kagglerの上位者のスコアはそれを遥かに上回っていた。
金メダルは、狙ってもとれるものではないかもしれないが、狙わないととれないのも確かだろうな。
2021年1月7日に、単独で金メダル圏内に入っているための必要条件を考えてみよう。
1.課題と提供されるデータを完全に理解すること。
2.Time-series API(Competition API Detailed Introduction)を完全に理解すること。
3.コンペのdiscussionと公開コードを完全に理解すること。
4.上記2件の論文と完全に理解すること。
これをやり遂げれば、少しは、金メダルに近づけるだろうか?
公開コードに、SAKTと、SAINTを意識したものがあるので、それをフォークさせていただいて、あとは、自力で進めるというのが当面の仕事になりそうだな。
12月4日(金)
Riiid!: 2,307 teams, a month to go
フォークしたTransformer Encode Modelを3日以内を目標に解読してみよう。
F. Cholletさんのテキストでは索引に載っていない。A. Geronさんのテキストでは、Transformer architecture, 554となっている。
Chapter 16: Natural Language Processing with RNNs and Attention
Attention Is All You Need: The Transformer Architecture
画期的な技術で、次のように書かれている。
... the Transformer, which significantly improved the state of the art in NMT without using any recurrent or convolutional layers, just attention mechanisms (plus embedding layers, dense layers, normalization layers, and a few other bits and pieces).
554ページには、Transformer architecture の模式図がある。元の論文を示す。


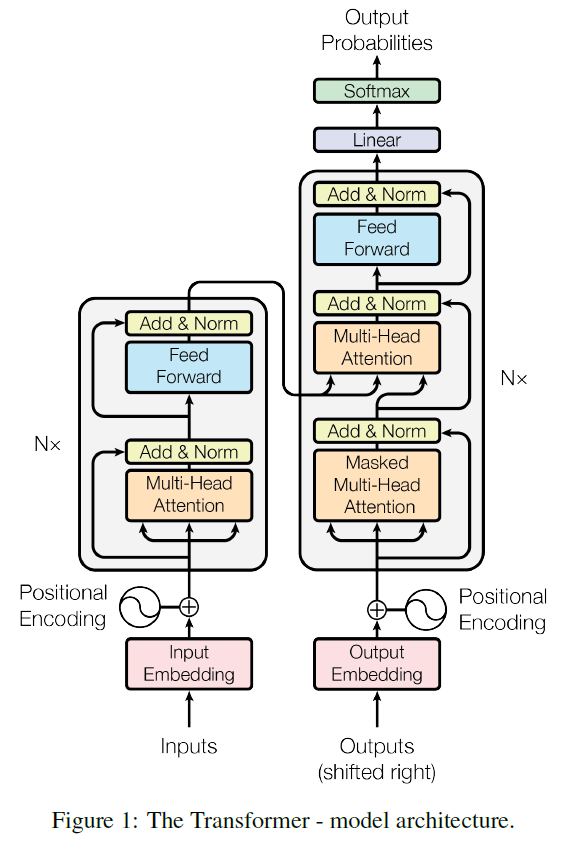
GitHubで’”Tranformer””で検索すると10,835 repository resultsと表示される。トップに出てくるrepositoryをクリックすると、そこには膨大な量の情報がある。どこに何があるか知っていればいつか役に立つだろう。
A. Geronさんのテキストでは10ページあまりにわたって説明されているが、それを読み込んでもコードが書けるわけではない。
フォークしたコードは、TensorFlowのチュートリアルhttps://www.tensorflow.org/tutorials/text/transformerのコードを用いているので、そちらで学ぶことにしよう。
TensorFlowのチュートリアルのタイトルが"Transformer model for language understanding"となっていて、text generationとattentionの知識があることを前提にしていると書かれている。
チューニングの合間に、チュートリアルと、フォークしたコードを比較している。
よくできているチュートリアルだと思う。
チュートリアルの事例はスペイン語から英語への翻訳で、言語間の相関を解析しているのだが、Riiid!の課題は行動(学習)パターンを解析することで、全く異質だと思うので、途惑うことばかりだ。そういうことからすると、フォークしたコードは、よく考えているなと思う。といっても、翻訳用のコードを、学習行動解析用に、どういうふうに変換しているのかは、まだ、まったく把握できていない。
12月5日(土)
Riiid!:2,344 teams, a month to go
<雑談>
F. Chollet氏のテキストに、AttentionやTransformerは無い。と思う。やはり、古いのだ。これに比して、A. Geron氏のテキスト(第2版:TF2)は、TF2というだけあって、2019年の前半くらいまでの情報が含まれていて、GPTやBERTも紹介されている。AnacondaにTF2がインストールできず、かつ、英語力も不足していたので、A. Geron氏のテキストを十分学べず、知らないことが多すぎるだけでなく、自分の勝手な解釈も多いことがわかってきた。目の前の話だと、encoder-decoderの理解の問題。variational auto encoderの印象が強くて、encoder-decoderに対して本来の意味とは全く異なるイメージを抱いていたようだ。情けないことだが、これが現実なのだ。
A. Geron氏のテキストでは、Figure 15-4にEncoder-Decoder networks、Figure 16-6にEncoder-Decoder network with an attention model、Figure 16-8にTransformer architecture、Figure 16-10にMulti-Head Attention layer architectureがそれぞれ図示されている。これで、encode-decoderとattentionとtransformerがつながった。
こんなんじゃ、だめだな。
本丸に切り込んでみよう。
解答者の解答履歴と行動履歴の中から、正答率との相関(正でも負でも)が高いものを選ぶこと、作り出すこと、見つけること、などが重要になるのだろうから、データをよく見て理解していく必要があるな。
どの情報が重要かは、最終的には、モデルに組み入れて確認することになるだろう。
TOEICについて、知らないよりは知っている方が良さそうだな。
TOEICをウイキペディアで調べてみよう。
試験問題の構成[編集]
2016年5月以降に実施されている試験問題の構成は次の通りである。
聞き取り(リスニングセクション)[編集]
聞き取り(リスニングセクション[28])は合計100問、所要時間は45分間である(但し、音声の長さに応じて所要時間が多少変わる場合があり、その場合は予め告知される)。
- Part 1 - 写真描写問題 (Photographs) - 1枚の写真を見て、その写真について放送される適切な英文を選ぶ。4択式で合計6問。
- Part 2 - 応答問題 (Question-Response) - 質問文が放送された後、それに対する応答文が3つ放送され、適切なものを選ぶ。合計25問。
- Part 3 - 会話問題 (Short Conversations) - 2人の会話を聞いて、その会話についての質問に対し最も適当な選択肢を選ぶ。質問文と選択肢は問題用紙に記載されている。4択式で合計39問。
- Part 4 - 説明文問題 (Short Talks) - ナレーションを聞いて、それについての質問に対し適切な選択肢を選ぶ。1つのナレーションにつき複数問出題される。質問と選択肢は問題用紙に記載されており、4択式で合計30問。
旧構成の Part 3、Part 4の問題文は印刷のみであったが、新構成では印刷されている問題文が音声でも読み上げられる。またPart 3、Part 4の1つの会話・説明文に対する問題数が2〜3問と不定であったものが、新構成ではそれぞれ3問に固定されている。
読解(リーディングセクション)[編集]
読解(リーディングセクション[28])は合計100問、制限時間は75分間である。聞き取り(リスニング[28])の終了と同時に読解(リーディング[28])の試験が開始され、読解(リーディング)の開始の指示は特になされない。
- Part 5 - 短文穴埋め問題 (Incomplete Sentences) - 短文の一部が空欄になっていて、4つの選択肢の中から最も適切な語句を選ぶ。合計30問。
- Part 6 - 長文穴埋め問題 (Text Completion) - 手紙などの長文のうち複数の箇所が空欄になっていて、それぞれ4つの選択肢から最も適切な語句を選ぶ。合計16問。
- Part 7 - 読解問題 (Reading Comprehension) - 広告、手紙、新聞記事などの英文を読み、それについての質問に答える。読解すべき文書が一つのもの (Single passage) が29問。「手紙+タイムテーブル」など読解すべき文書が2つもしくは3つのもの (Multiple passage) が25問。それぞれ4択式。
question.csvのpartは、Kaggleのデータの説明に、the relevant section of the TOEIC test.と書いてあるので、上記の1~7を指すのだろうが、lectures.csvのpartは、top level category code for the lectureと説明されていて、よくわからない。
今のモデルの現状は、LB=0.736である。
来週末までに、流すデータを見直して、0.74+にしたいと思う。
12月6日(日)
Riiid!:2,383 teams, a month to go : gold 0.797+, silver 0.776+
<雑談>
LightGBM系とDNN系についてちょっと考えてみよう。機械学習とディープラーニングの比較のつもりだが、ディープラーニングは定義上、機械学習に含まれるようなので、このような表現にした。ただし、LightGBMはDNN以外のモデルというつもりで示しており、このモデルに限るということではない。Riiid!コンペもそうだが、表データのコンペでは、LightGBMを使ったコードがたくさん公開される。同じツールを使っていても、データの前処理、後処理、アンサンブル、ハイパーパラメータなど、の最適化の程度によってスコアはばらつく。DNNを使った場合も同様なのだが、ばらつきは概してLight GBMのグループの方が小さい。ハイスコア側は公開コードには現れないので実際のところはわからないが、見える範囲ではそう感じる。そこで知りたいのはばらつきの大きさやその原因ではなく、ハイスコアの限界はどこにあるか、LightGBMとDNNのどちらのスコアが高いのか、ということが、誰もが知りたいことである。DNNと書いただけだと、LightGBMに勝ち目はなくDNNの勝利となるだろう。最終的にどちらが高いスコアに達するかというときに、もしかすると、最高位は、両方のグループを合わせたアンサンブル、LightGBM系+DNN系かもしれない。多分そうなんだろうと思う。特性の異なるモデルを適切にアンサンブルすることによって最高のスコアが得られるということなのだろうと思う。Kaggleコンペに限らず、コンペの順位は主催者が選んだテストデータに対するスコアの順位で決められるので、話は複雑である。submitしたモデルの中から選んだ数件のモデルで最終スコアを争うのではなく、submitした全てのモデルに対して最高スコアを争うことにすると、勝者の範囲は狭くなるだろう。ある意味、面白さは減るかもしれない。自分が勝者になるかもしれない!、という期待感も小さくなるかもしれない。番狂わせがあるというのは、多くの場合は、public_test_dataに対してoverfittingになっているかどうかということであって、よくないモデルでも勝てるということではない。この雑談を書こうと思ったのは、1つには、単独のモデルで勝つのは難しいということ、ベストモデルにこだわるなということである。MoAでいえば、TabNetが話題になり、TabNetで競うようなところもあったようだが、つまるところ、同じモデルを使っても、前処理、featureの選び方・作り方により、もちろんハイパーパラメータによってもスコアは変わるので、結局は総合力ということになる。だから、今回も、特定のモデルにこだわることなく、種々のモデルを試すこと、データベースをより深く理解すること、time-series APIを正しく理解することなど、様々な要素に対する取り組みが必要だということであると思うが、どこまでできるだろうか。
MoAコンペの優勝チームの手の内紹介記事を見た。難しくて理解できない。やっていることは、文章と模式図から、なんとなくわかるが、どうやってそういう発想になったのか、発想できたとしてどうやってコード化したのか、トレーニングはどうやって行ったのか、皆目わからん。こういう人と勝負して勝つにはどうすれば良いのだろうか。
GitHubに用いた7つのモデルを公開しているというので見に行ったら、この優勝チームのリーダーは、既に、162のrepositoriesを作っている。大半はフォークしたものだが、オリジナルもいくつかある。Kaggleコンペの優勝者のモデルもいくつかフォークしている。そうなんだ、オープンソースライセンスが、今のプログラムの流通のベースになっているし、Kaggleのサイトの中も同様なんだ。といっても、コンペサイトだから、なんでもオープンにするわけにはいかない。
チューニングしないとパラメータの最適値が分からないし、プログラムの各部分が正しく機能しているのかどうかを確かめるためにもチューニングは適切に行っていく必要がある。
やっと、0.74+になったが、原作者は0.767まで向上している。
Riiid! Researchの論文をチェックして、エンコーダ、デコーダに入力しているデータを特定しようとしているのだが、まだ、まったく、つかめない。
12月7日(月)
Riiid!:2,415 teams, a month to go:gold 0.797 over, silver 0.777 over
今のモデルのパラメータのおおよその適正範囲がわかってきたので、今日は、流すデータ量を単純に増やしてみる。具体的には、10Mでパラメータ調整し、そのまま、データ量だけ増やすということ。20M, 50M, 100Mと増やしてみたいが、100Mをやってみてからその次を考える。
その後で、再度、パラメータの適正範囲を探索してみよう。
10Mを100Mにすると、val_AUCは、0.8-0.9%程度大きくなった。
この増分は、モデルとハイパーパラメータと流すデータの質にも依存すると思うし、そもそもどのレベルにあるのかにもよるだろう。この結果は、val_AUC=0.75+で得られたものである。現状でも、かなり良くできたモデルなのかもしれない。
ここから、ハイパーパラメータを変更するのは、ベースラインを上げてからにしようと思う。入力データの検討とモデルのアーキテクチャの検討をして結果を出さなければ、0.76+以上は望めないように思う。
最終目標の0.82+は、はるか彼方である。
100Mのデータを通した結果のcommit中に、トラブル発生。3時間以上かかった計算のやり直し。計算とcommit合わせて、約7時間のロスだ。ただで使わせいただいているのだから文句は言えないというところか。残念だな。
もう1度100Mをやるには、さらに6時間以上GPUを使うことになる。
一足飛びに100Mをやるのではなく、着実に進めなさいということを暗示しているのだと思って、10Mから始めて20M, 30Mという順で、結果(public LB)を出してみることにしよう。今の条件では、10Mのデータでも、2エポック目でval_AUCは最大値になっていて、1エポック目との差も0.5-1.0%程度なので、時間節約のために1エポックで結果を出してみる。
12月8日(火)
Riiid!: 2,453 teams, a month to go
投入したデータ量(目安)とスコアの関係(1エポックでtraining終了)
val_AUC public LB
10M 0.748 0.744
20M 0.751 0.749
30M 0.755 0.748
40M 0.755 0.750
60M 0.757 0.755
100M 0.758 ?
このような相関が常に成り立つかどうかわからないが、通常の条件検討は効率優先で、20~30M程度でテストして、最終段階では、データ量を増やすことによって少しでもスコアを上げるのに役に立つかもしれない。といっても、メモリーオーバーで停止するとか、改善につながらない可能性も否定できない。データのばらつきにも注意が必要。
ちなみに、Kaggle kernel内ですべての計算を行っているのだが、transformerモデルのユニット数や層数は最小限に近いレベルに設定しないとメモリーエラーが生じ、それでも、100Mのデータを流すと、1エポックでも、計算を完了するには、3時間くらいかかっている。
<メモ>
MoAコンペの、submitしたモデルを眺めていて気付いたこと。NNモデルのdropoutの数値を下げてweight_decayを上げると、単独モデルのpublic LBスコアは良くなったが、他のモデルとアンサンブルしたときには、そのdropoutの数値を下げてweight_decayも下げたモデルの方が、public LBスコアも最終的なprivate LBスコアも良かった。といっても、それはもちろん、結果がそうだったというだけのこと。それを見越して最終モデルを選んだわけではない。単独のスコアは良いのに、アンサンブルしたら悪化するモデルのことは、discussionでも話題になっていた。dropoutは、アンサンブルの一種とみなされる。ユニット数を変えながら訓練しているので、様々なユニット数のモデルを組み合わせているのと似ているということだ。だから、CVが同じでも、dropoutの割合が高いモデルの方が、汎用性は高いと考えられる。これまでの経験では、dropoutの割合が高いモデルの方が、private teat dataに対しては良い結果となっている。今使っているTransformerモデルでは、dropoutを変えても有意差がわからない。モデルの安定性の問題かもしれない。今使っているモデルのval_AUCは、計算後とcommit後とで、±0.3%くらいは変動しているようである。
同じことの繰り返しはやめよう、じじくさい。
transformerの論文でも読もう

なんちゃわからん。
RNNがわかっとらんからな。
以下は、A. Geronさんのテキスト第2版からの転載です。
p.501 Input and Output Sequences
An RNN can simultaneously take a sequence of inputs and produce a sequence of outputs. this type of sequence-to-sequence network is useful for predicting time series such as stock prices: you feed the prices over tha last N days, and it must output the prices shifted by one day into the future.
Alternatively, you could feed the network a sequence of inputs and ignore all outputs except for the last one. In other words, this is a sequence-to-vector network. For example, you could feed the network a sequence of words corresponding to a movie review, and the network would output a sentiment score (e.g., from -1 [hate] to +1 [love]).
Conversely, you could feed the network the same input vector over and over again at each time step and let it output a sequence. This is a vector-to-sequence network. For example, the input could be an image (or the output of a CNN), and the output could be a caption for that image.
sequence-to-sequenceと、sequence-to-vectorと、vector-to-sequenceについて、なんとなくわかった。
ここからが本命のEncoder-Decoderだ。
Lastly, you could have a sequence-to-vector network, called an encoder, followed by a vector-to-sequence network called a decoder. For example, this could be used for translating a sentence from one language to another. You would feed the network a sentence in one language, the encoder would convert this sentence into a single vector representation, and then the decoder would decode this vector into a sentence in another language. This two-step model, called an Encoder-Decoder, works much better than trying to translate on the fly with a single sequence-sequence RNN: the last words of a sentence can affect the first words of the translation, so you need to wait untill you have seen the whole sentence before translating it. We will see how to implement an Encoder-Decoder in Chapter 16.
ふむふむ。なんとなく、Encoder-Decoderのことがわかってきたような気がする。
A. Geronさんのテキストの第16章 Natural Language Processing with RNNs and Atentionを理解しよう。
全40ページだ。
読書百遍義自ずから見る、といきますか。ちなみに「見る」は「あらわる」と読む。
で、読んでいるのだが、tokenizer, GRU, embedding, LSTM, ...勉強不足でわからん。Chapter 15: Processing Sequencies Using RNNs and CNNsにもどらないと、・・・。
40+25=60ページになる。必要なことだが、まず、40ページを、最後まで読もう。
12月9日(水)
Riiid!: 2,487 teams, a month to go
今日は朝からA. Geronさんのテキストの第16章を勉強している。
現状のモデルでもチューニングしたいことはたくさんあるのだが、KaggleのGPUの残り時間がわずかになっているので、今日はチューニングの計算をしていない。
するとどうだろう、時間が余る。テキストを読んでいても時間が長くなると頭が飽和して先に進めなくなる。などと、うだうだいってサボっていては金メダルに近づけないので、テキストを読む。
545ページにEncoder-Decoderのコードが20行あり、その説明の最初にこう書かれている。The code is mostly self-explanatory, but there are a few point to note.
それはそうだろうな。難しい数式も、難しい理論も、なさそうだ。あるのは、等式: =, tuple: ( ... ), list: [ ... ]の他に、英単語が並んでいるだけ。
encoder_inputs, keras.layers.Input, shape, dtype, np.int32, decoder_inputs, sequence_length, embeddings, keras.layers.Embedding, vocab_size, embed_size, encoder_embeddings, decoder_embeddings, encoder, keras.layers.LSTM, return_state, True, state_h, state_c, sampler, tfa.seq2seq.sampler.TrainingSampler, encode_cell, keras.layers.LSTMCell, output_layer, keras.layers.Dense, tfa.seq2seq.basic_decoder.BasicDecoder, sampler, final_outputs, final_state, final_sequence_length, initial_state, Y_proba, tf.nn.softmax,
単語を書き並べてみた。
547ページのBeam Searchとは何か。
約2ページにわたる解説のまとめが以下のようになっている。
With all this, you can get good translations for fairly short sentences (esoecially if you use pretrained word embeddings). Unfortunately, this model will be really bad at translationg long sentences. Once again, the problem comes from the limited short term memory of RNNs. Attention mechanisms are the game-changing innovation that addressed this problem.
だとさ。技術的な中身が理解できないまま、表面的な理解で読み進んでいるだけのような気がする。
次は、549ページからのAttention Mechanism
自然言語処理としてのTransformerの説明のようだし、Riiid!コンペの課題に対してイメージが湧かない。もちろん、イメージが湧くまで読み込んでいないということかもしれないが、TOEICの問題に対して正答する確率を求めることと、翻訳とか、文章生成とか、要約とかが全く結びつかないので、このへんで、テキストの学習は中断する。百篇どころか一遍読んだかどうかというところで中断とは情けないが読んでいても明らかに脳のニューロンを素通りしている。
Riiid! AI Researchの論文を読んでみよう。
SAINTの0.78、SAINT+の0.79を、当面の目標にしよう。今は0.755だから目標高すぎ!
12月10日(水)
Riiid!:2,516 teams, a month to go
昨夜、Riiid!コンペに対応している(らしい)プログラムコードをGitHubで見つけ、ダウンロードした。Kaggle kernelにアップロードして実行し、trainingまで動作することを確認した。途中経過をsaveし、継続してtrainingできるように組まれており、制限時間を気にせず、十分なtrainingが可能ということで期待して実行してみた。途中でエラーが発生しないように変更した以外、パラメータは変更しなかった。GPUを使用し、10Mのデータ量で、1エポックの80%くらい走らせてみた。約50分くらいかかり、val_AUCは、0.65+で収束しそうな感じであった。スコアはともかく、プログラムコードは、課題に合うように考えて、しっかり書かれているようで、参考になりそうだ。
今日、GitHubからのモデルのハイパーパラメータを見直してtrainingした結果、val_AUCは0.74+レベルになった。計算時間が長かったのは、ユニット数が多かっただけである。ただし、1エポックでの比較なので、ユニット数を減らすのが良いかどうかはわからない。土曜日にGPUが使えるようになれば、ユニット数が多い場合のtrainingをやり直し、(ユニット数、エポック数、val_AUC)等について相関を調べる予定である。
GitHubからのコードとKaggleの公開コードの比較だが、使っているデータもモデルの構造も少し異なっているので比較できないが、いずれのコードも自分のレベルを超えており、しっかり学びたい。
今日は、SAINTの要点を把握し、実際のデータとの関係を把握しよう。
重要な要素は2つある。
1つは、Exercise embedding sequenceをEncoderに、Responce embedding sequenceをDecoderに分けて流す(入力する)こと。
Exercise embedding sequence --> enter the Encoder
Response embedding sequence --> enter the Decoder
2つめは、ExercisesとResponcesの複雑な関係を、deep self-attentive computationsを使って、効果的に捕える(capture)こと。
Ii : interactions Ii = ( Ei, Ri )
Ei : denotes the exercise information, the i-th exercise given to the student with related matadatasuch as the type of the exercise
Ri : denotes the responce information, the student responce ri to Ei with related metadata such as the duration of tome the student took to respond
ri : denotes the student responce, is equal to 1 if their i-th responce is correct and 0 if it is not
Thus, SAINT id designed to predict the probability
P( rk = 1 | Ii, ..., Ik-1, Ek )
12月11日(金)
Riiid!:2,543 teams, 28 days to go
SAINTに関連するDiscussionで、全データ(100M)を用い、d_modelもwindow_sizeもかなり大きく(ユニット数を多く)しないと、0.78-0.79には、届かないようなことが書かれている。SAINTの論文に書いてある条件では、メモリーアウトで計算できない。まあでも、解は1つではないはずだ。
MoA:varification終了により順位確定
コンペの結果が確定し、Silver medalとKaggle Competition Expertの通知メールがきた。
1年前の12月12日、手帳に、「ビリでもいいからリーダーボードにのりたい」と書いてある。そのページには、YOLO、3D、6D、バウンディングボックス、KITTI、などの単語が書きつけられている。1月には鋼材表面の欠陥検出、2月には高額の賞金がかかったfake画像検出、3月にはARC、4月は大学受験数学に集中、5月はARC再開、6月中旬からTReNDS、7月にはPANDA、7月末からSIIIM、COVID-19、LandMark、Bird、OSIC、RSNA、LyFT、MoA、Riiid!、・・・。
12月12日(土)
Riiid!:2,601 teams, 27 days to go
これからも何度も起きると思うが、ハイスコア(自分のレベルと比較して)の公開コード(0.765)が投稿され、60番くらい下がった。
今のコードのポテンシャルを生かせず、0.755を超えられず、苦戦中。
ユニット数を文献やDiscussionでの値に近づけて設定して計算してみた。1エポックに4時間くらいかかる条件だったが、可能性を調べるために計算を初めて見た。そうすると、途中からlossの下がり方、AUCの上がり方が悪くなり、2時間くらい経過すると、lossとAUCが反転し始めた。一時的なものかと思い、しばらく様子を見たが、だめなようで、中止した。GPUがリセットされ34時間まで使用可能になったので、意気込んで計算し始めたのだが、残念な結果となった。
ギャー、0.772が投稿された。目標が0.78以上だから関係ない!と、強がってみる。
気になったのは、その公開コードの前書きに、12Mのデータで0.770-0.772を得たとなっていることだ。
10M使って0.744、60M使って0.755では、話にならんな。
今日は、60Mのデータにこだわって計算して、思うような結果が得られず(実のところ、非常に良い結果が得られそうな気がしていた。SAINTの論文とKaggle Discussionでの話とで一致する条件を選んでいるから、間違いないと思った)、結局10時間近くもGPUを消費してしまった。大きなデータ量で良い結果が出れば言うことなしなのだが、結果が出なかったときの損失は非常に大きく感じる。
12Mのような、少ないデータ量で、もっと基本的なところを押さえていこう。
60Mでの失敗は、特定のパラメータ群を一気に変更して、うまくいかなかったということだが、それは、関連する他の条件があって、それらも同時に変更する必要があった、ということなのだろうと思う。そのパラメータが何であるか、それを探索して調整する必要がある、ということなのだろうと思っている。
優先順位を決めておこう。
1.Transformerのスレの内容を確認する。まだ手を付けることができていなことがいくつかあるが、このスレには、具体的な解決につながるヒントがありそうだ。
2.1.を終えるまでは、次の段階に移らないことにする。そのスレの何か所かを拾い読みし、その情報で対応してきたのだが、全部きちんと読まないとダメな気がしてきた。SAINTの論文を読むと、わかったような気になるが、プログラムとの対応は、いまいちわからず、具体的な問題解決につながらないで困っている。
12月13日(日)
Riiid!
今日は、transformerに関する情報収集の前に、やりかけのチューニングを片付けようとしてドツボにはまった。GPUの使用時間を今日だけで14時間以上消費し、残りは8時間になった。
ユニット数を多くしすぎて失敗した件は、原因がはっきりわかったわけではないが、learning rateのスケジューリングプログラムを使うことで、とりあえず、解消した。
それならばと、意気込んで、60Mのデータを流してハイスコアの可能性を調べたものだから、時間ばかりかかって、成果は殆どなかった。現状のプログラムでは、0.76+が限界であることがわかった。0.77+が次々と公開されている状況では話にならないので、transformer関する情報収集と検討を明日からやる。
今週の目標は0.76だったが、実現したのは0.757までだった。
来週の目標は0.77に設定しているので、金曜日までにプログラムに手を入れて、土日に結果を出したいと考えている。
12月14日(月)
Riiid!:2,678 teams, 25 days to go
SAINT benchmarkというというトピックに関する意見交換を読んでいるのだが、topic autherは0.795、transformerのbaseline code(0.715)を公開した人は0.784、に達していて、毎日のようにスコアは向上しているようだ。
give and takeが進んでいて、性能に直結するような情報の交換が行われている。公開コードを共有するのと同様に、ハイパーパラメータの具体的な値、モデルの構造、プログラムの一部などの情報を交換している。
読み込むべきは、discussionでも論文でもなく、コード自体である。英語力を鍛えてきたように、プログラミング力を最優先に鍛えていこう。
プログラミング力の無いところに金メダルは無い。
12月15日(火)
Riiid!:2,722 teams, 24 days to go
昨夜、0.78のコードが公開されていた。SAKTとLGBMのアンサンブルである。SAKTはtrain済みのパラメータを読み込むだけで、LGBMはtrainを含む。SAINTを完成させないとその先は無いと思って、フォークは少し控えていたのだが、手を出してしまった。すでに、150チームくらいが並んでいる。別の方法でそこに到達したチームもおられるが、ちょいと乗っかったチームと見分けはつかない。その大部分はメダル圏内だが、まだ先は長いので、コンペが終わるまでには、みんなメダル圏外だろうな。何度も見てきた風景だが、そこに自分も入っている。
積読してあった「ゼロからはじめるデータサイエンス:Joel Grus著、菊池彰訳」に目を通し始めている。原著は2015年、訳本は2017年の発刊のようである。機械学習のテキストとしては新しくはないが、Python、データの可視化、線形代数、統計、確率、仮説と推定、勾配降下法、データの取得、データの操作、機械学習、・・・と続いていて、基礎を学ぶには最新でなくても良いと思う。2年以上前に何冊か購入したうちの1冊だが、数ページ目を通しただけで放置したようだ。最低でも購入日や購入書店名、読み始めればその日付などを書くのだが、そのどれもが記入されていないほど、気に入らなかったのだろうと思う。今見ると、機械学習初心者には向かない(基礎の部分が延々と続き、機械学習の話が始まるのは160ページを過ぎてからである)が、実務者には必携の書物だなと思う。
F. CholletさんのテキストもA. Geronさんのテキストも英文のまま読んでいる。コードが英文で書かれているので、とにかく、英単語が日本語に変換することなくすっと頭に入るようになりたいと思ってそうしているのだが、それにはデメリットもある。とにかく、進むのが遅い。それと、今、訳本を読み始めて感じたのだが、英語のテキストだと本文を読むのに疲れて、コードへの集中力が高まらない。対して訳本は、コードに集中できる。原著だと、コードを理解するために本文を読むのは英英辞典を使うようなものだが、訳本だと、コードを理解するときに、コードの英単語にはかなり慣れてきて辞書は要らないので、コードの機能を理解することに集中できるというメリットがある。結局は、学習の積み重ねが重要ということになるのかな。
ちょっと戻るが、FORTRANやBASICを使ってプログラミングしてきたから、Pythonなんてチョロいと思っていたのが良くなかったな。なんでもかんでもFORTRANではどうだったかな、BASICではどうだったかなと考えて、無理に置き換えて理解しようとしてつまづいたような気がする。CとかC++でもやっておけばよかったのかもしれないが、そこはまったく手を付けることがなかった。
雑談はこのくらいにしてプログラミングに集中しよう。
つい、悪い癖が・・・。0.780のコードをフォークして、チューニングしている自分がいる。 チューニングで負けないことも重要なのだ、ということにしておこう。
12月16日(水)
- Riiid AIEd Challenge
- , 2,760 teams
- , 23 days to go
今、0.780に約220チーム(166~384)が並んでいる。
ここから脱出しようともがいている。その結果、今、0.780の先頭にいる。
今日は、0.780で先頭のまま、終わってしまいそうだ。
「ゼロからはじめるデータサイエンス」
1章のイントロダクションの中をウロウロしている。辞書形式のユーザーリストから始まる。idとnameが並んでいるだけ。交友関係を調べてグラフ化する。
users = [
{ "id": 0, "name": "Hero"},
{ "id": 1, "name": "Dunn"},
こんな感じで並んでいるのだが、いかにもめんどくさそう。
この辞書形式は、パラメータの設定で使われる。
Riiid!のコンペで使っているtrain_dataの情報をdictionary形式で表現すると、
data_types_dict = { 'timestamp': 'int64', 'user_id': 'int32', 'content_id': 'int16', 'content_type_id':'int8', 'task_container_id': 'int16', 'user_answer': 'int8', 'answered_correctly': 'int8', 'prior_question_elapsed_time': 'float32', 'prior_question_had_explanation': 'bool' }
目の前の課題に直結した事例で説明されていれば、だれでも食らいつくだろうが、内容に興味が持てない場合には、勉強が捗らない。これが、自習の難しさの重要な要因の1つだろうな。
次は、交友関係をタプルで表したものが現れる。
friendships = [(0, 1), (0,2), (1, 2), (1, 3), (2, 3), ..., ...]
さらに各ユーザーが持っている興味を表にしたもの。
interests = [
(0, "Hadoop"), (0, "Big Data), ..., (1, "NoSQL"), ..., (2, "Python"), ...,
]
書くのが面倒だからめちゃくちゃ省いた。
書いてることもめちゃくちゃになってきた。
次に移ろう。
第2章のPython速習コースだ。
19ページ:空白によるフォーマット
知らなかった:
丸カッコ、角カッコの内部では空白が無視されるので、長い行を折り返して書けます。
コードの右側が見えないとき、適当に切断して折り返したら、誤動作したことがあった。これは、簡単なことだが、重要だ。
20ページ:モジュール
importの便利な機能、import *には要注意。
不用意にモジュール全体をインポートすると、自分で定義した変数を意図せずに上書きしてしまう点に注意が必要。
21ページ:関数
def double(x):
return x * 2
名前を持たない短い関数(ラムダ:lambda)がよくわからない。
y = apply_to_one(lambda x: x + 4)
デフォルト引数という使い方:こういうのは知らないと困る。
def subtract(a=0, b=0):
return a - b
subtract(10, 5) # =5
subtract(b=5) # =-5:b=5だけが関数subtractに送られると、a=0とb=5が代入されて、0-5=-5 が返される。
22ページ:文字列
バックスラッシュに注意
複数文字列については理解できない。
29ページ:例外
try:
print 0 / 0
except ZeroDivisionError:
print "cannot divide by zero"
29ページ:リスト
Pythonの最も基本的なデータ構造は、おそらくリストでしょう。:と書かれている。
これは、イロハのイですかね。:自分は、これを理解できていないがゆえに、コードの理解/解読/書き換え等に手間取っている、苦しんでいる。
integer_list = [1, 2, 3]
heterogeneous_list = ["string", 0.1, True]
list_of_lists = [integer_list, heterogeneous_list, [ ] ]
list_length = len(integer_list) # 3
list_sum = sum(integer_list) # 6
24ページ:リストの続き
x = range(10) # list [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
zero = x[0] # 0番目 インデックス0の要素、すなわち0
one = x[1]
nine = x[-1]
eight = x[-2]
x[0] = 1 # list [-1, 1, 2, 3, 4, 5, 6, 7, 8, 9]:ここで、xが変更されたことに注意!
first_three = x[ :3] # 0番目から3番目までの要素:[-1, 1, 2]
three_to_end = x[3: ] # 3番目から最後までの要素:[3, 4, 5, 6, 7, 8, 9]
one_to_four = x[1:5]
last_three = [-3: ] # 最後から3つ前までの要素:[7, 8, 9]
without_first_and_last = x[1:-1]
copy_of_x = x[ : ]
...
x = [1, 2, 3]
x.extend([4, 5, 6]) # xは[1, 2, 3, 4, 5, 6]になる。
[ ]が( )に囲まれている、[ ] が( )の中にある、( [ ] )、こういうのを見ただけで気分が悪くなる。違和感を感じてしまう。それぞれの役割が理解できていないからだろう。
x.extend( )が定義で、extendしたいリスト[ ]を、( )の中に記述する、というだけのことか。y = [4, 5, 6]としておけば、x.extend(y) = x.extend([4, 5, 6])。
x = [1, 2, 3]
z = len(x):z = len([1, 2, 3])
x, y = [1, 2]:x=1, y=2
_, y = [1, 2]:y=2:こういう表記 "_," は違和感を感じるのだが、こういうのを多用したコードから、つい、目をそらしてしまう。慣れてしまおう。
25ページ:タプル
読めばわかるかな。
26ページ:辞書
2,3写しておく。
grades = { "Joel" : 80, "Tim" : 95 }
joel_grade = grades["Joel"]
少しぼやけてきた。辞書は、キー”Joel"と値80を関連付けて格納したもの。
27ページ:defaultdictクラス
文章document中の単語wordの数を数えるcount。
word_counts = { }
for word in document: # documentの端から順にwordを取り出す
if word in word_counts: # 取り出したwordが辞書にあれば1を追加する。
word_counts[word] += 1
else: # 取り出したwordが辞書になければwordを登録し1とする。
word_counts[word] = 1
コメントは自分が適当につけたもので、これでよいかどうかわからない。
キーが登録されていることが前提のようなコードなので、最初の行でword_countsを初期化しているのが腑に落ちない。
defaultdictというのを使えばよいらしい。
29ページ:Counterクラス
単語の出現数を数える問題は次の1行で完成するとのこと。
word_counts = Counter(document)
出現数の多い順に要素を返すmost_commonメソッドが用意されているとのこと。
for word, count in word_counts.most_common(10):
print word, count
29ページ下:集合
大量のデータの中から要素が含まれるかチェックする必要があるなら、集合は最も適したデータ構造とのこと。
最後に、集合より辞書やリストの方が頻繁に使われます、と書かれている。
30ページ:実行順制御
ifによる条件判定
whileループ
forとinの組み合わせ
for x in range(10):
print x, "は、10より小さい”
より複雑な制御が必要ならcontinueやbreakも利用できる、とのこと。
31ページ:真偽
True, False
次は上級Pythonと書いてある。
12月17日(木)
Riiid AIEd Challenge, 2,787 teams, 22 days to go
急に順位が下がったと思ったら、0.781のコードが公開されている。
0.780のコードとの違いは、主に、流すデータ量の違いで、0.780のコードは、(12M、fraction=0.15)、0.781のコードは、(20M、fraction=0.09)、となっている。
これを実現するために、featureを減らしている。featureを減らさないでこれだけのデータ量を流そうとするとエラーが出る(確認済み)。
今(13時)調べると約80チームが0.781に、約200チームが0.780に並んでいる。
Discussionによれば、現在1位の人は、SAINTベースで、7位の人はLGBMベースのようである。重要なのは、feature engineeringのようだ。
0.780が0.781になったのは、データ量が12Mから20Mに増えたのが原因ではなく、featureを減らしたことが原因であるかもしれない。その効果を打ち消すようなfeatureの組があって、片方を削除したことで、他方の効果が現れたのかもしれない。
といっても、効果は+0.001です。小さくはないが、大きくもない。今の段階では、データ量を増やすことよりも、featureを工夫することが重要だろうな。
LightGBM:
優れものらしいが、パラメータが多くて、性能を発揮するには、データ、前処理、プログラム構成などの要素に加えて、LGBMそのものの特性・特徴をよく理解しておかなければならない。ということだけど、具体的にどうすればよいのか。
ドキュメント量は非常に多く、パラメータの定義を見ても、パラメータの設定範囲がわかりにくいものもある。optunaの開発メンバー、小嵜氏のブログを見ると、次のようなコードが示されている。これで、チューニングにおいてこれらのパラメータが重要だろうと推測される。
param = { 'objective': 'binary', 'metric': 'binary_logloss', 'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0), 'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0), 'num_leaves': trial.suggest_int('num_leaves', 2, 256), 'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0), 'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0), 'bagging_freq': trial.suggest_int('bagging_freq', 1, 7), 'min_child_samples': trial.suggest_int('min_child_samples', 5, 100), }このコードであれっと思った箇所が2つある。1つは、num_leavesの最大値が256となっていること、もう1つは、lambdaの設定値の最大値が10となっていることである。
前者については、300以上に設定している例をよくみかける。性能アップにはnum_leavesを大きくすべし、と書かれている記事が多いからだろうと思う。
後者については、設定範囲は0-1と、勝手に思いこんでいた。
これを見ると、optunaというものを使ってみたくなるな。
投入できるデータ量を増やすために、featureを見直した結果、良いか悪いかはわからないが、これまでの条件では極端なオーバーフィッティングになることがわかった。L1,L2も効かないので、num_leavesから見直しを始めた。フォークしたときの350を、そのまま使い続けていたがこの際だから、再出発のつもりで、デフォルトの32から検討している。
num_leaves=32:train_auc=0.782, val_auc=0.767でピーク:目標の0.772+は遠い。
num_leaves=64:train_auc=0.787, val_auc=0.769:まだまだだが、num_leaves=350の結果をわずかではあるが上回った。葉っぱの枚数が多ければ良いというものではないことを実感した。NN系のoverfittingには慣れているが、機械学習系はこれまでoverfittingを実感することはなかった。
num_leaves=96:train_auc=0.788, val_auc=0.768:これ以上良くならない。
「ゼロからはじめるデータサイエンス」J. Grus著、菊池彰訳
第5章 統計
代表値:
通常、データはどこが中心となっているのかに興味がある。多くの場合、値の総和をデータ数で割った平均値を用いる。
def mean(x):
return sum(x) / len(x)
場合により、中央値medianが必要になる場合もある。
def median(v):
n = len(v)
soeted_v = sorted(v)
midpoint = n // 2
if n % 2 == 1:
return sorted_v[midpoint]
else
lo = midpoint - 1
hi = midpoint
return (sorted_v[lo] + sorted_v[hi]) / 2
平均値meanはデータ内の外れ値に対して中央値medianよりも敏感である。
繰り返し語られる話題:1980年代中ごろ、ノースカロライナ大学の卒業生で最も高い初任給を得られた専攻は地理学であった。それは、NBAのスター選手(良い意味の外れ値を提供)、マイケル・ジョーダンが原因である。
モード(最頻値)も重要である。
12月18日(金)
Riiid AIEd Challenge, 2,823 teams, 21 days to go
当面は、公開コードによって増殖中の0.781を超えないとメダルは無い。
0.781を超えようと思って昨夜セットした計算は1000ラウンドで収束したが、commitは3500ラウンドを超えても収束しない。どうなることやら。
結局、4700ラウンドの手前で終了したが、8時間くらいかかった。やれやれ。
なんとか、0.781の列の前の方に着地した。
val_AUCからは、0.782になってもよさそうなのだが・・・。
commit中にラウンド数が増えるとともに、val_aucも上がったので喜んでいたのだが、期待通りにならなかった。
どうも、commit中にオーバーフィッティングが増幅されているようだ。
12月19日(土)
この1週間のGPUの割当は30時間となっている。少ないな!
Riiid AIEd Challenge, 2,854 teams, 20 days to go
オーバーフィッティングを避ける方法の1つとして、少なめのラウンド数で止めてsubmitしてみた。val_aucがほぼ同じで、train_aucは低く抑えられた。
しかし、LBの改善には結びつかなかった。
再現性が良くない。
commit中にoverfitting気味になるかと思えば、明らかに小さな値になることもある。
現在の条件で再現性を調べてみる。
誰かの記事にならって6Mくらいのrawデータ量でチューニングしてから、データ量を増すことにして、チューニングをしてみたが、ラウンド数が少ないと、ばらつきのために違いが見えにくく、6Mのデータでも時間がかかる。パラメータによっては、ラウンド数が増えてから効果が現れてくるものもあるので、早い段階での数値を比較していると判断を誤ることがある。これは結構深刻な問題である。
フォークしたコードのLBスコアを0.001上げられずに苦しんでいる自分がいる。
昨日はcommit中のスコアが高くなり、今日はcommit中のスコアが低くなった。
結果として、どちらの場合でもLBスコアの向上に結び付いていない。
feature engineeringをやれと言われているような気がしてくる。
12月20日(日)Riiid AIEd Challenge, 2,890 teams, 19 days to go
チューニングによるスコアが頭打ちになってきたので、featureの選択や処理/追加作製方法を学ぼうと、notebookを検索してみた。
以前にも参考にさせていただいたコードが、バージョンアップされていた。EDAとBaseline modelという内容はそのままだと思うが、以前に見たときは、計算するところで終わっていたように思うが、submitできるようになっている。
コンペで競うことを目的に参加している人が大半だと思うが、コンペ参加者のために、EDA、解法例、submittするためのコード、などを公開することを目的とされている人がおられるのではないかと思う。非常にありがたいことである。
featureの選択をやっているが、難しい。
12月21日(月)
Riiid AIEd Challenge, 2,923 teams, 18 days to go
今日もfeatureの選択をやっている。
いろいろやっていて、面白い現象がおきた。
投入するfeatureの組み合わせによって、Feature Importanceの分布が大きく変化したのである。分布の見た目の違いほどには、Val_AUCは変わらなかったが、少し大きくなる組み合わせも出てきた。LBも改善されることを期待しているが結果はまだ出ていない。
残念、少し良い結果をcommitしている最中にエラーが発生した。
計算からやり直しだ。
12月22日(火)
Riiid AIEd Challenge, 2,960 teams, 17 days to go
feature選定検討中
12月23日(水)
Riiid AIEd Challenge, 2,994 teams, 16 days to go
12月18日に0.781に着地して以来、更新できていない。
それも、100%借り物のコードである。
LGBMについては、少しは理解が進んだと思うが、思考錯誤の時間さえあればだれでもできそうなことしかできていない。
feature engineeringをやっている、と感じられるコードをみていると、val_AUCの値も、feature importanceの分布も、用いるfeatureによって大きく変化しているのがわかる。
それらの変化の大きさと比べると、LGBMのチューニングによる効果は小さい。
といっても、'gbdt'の中でのことであって、'goss'や'dart'までは試していない。
LGBMのサイトの、Parameters Tuningには、次のような項目がある。
For Better Accuracy
-
Use large
max_bin(may be slower) -
Use small
learning_ratewith largenum_iterations -
Use large
num_leaves(may cause over-fitting) -
Use bigger training data
-
Try
dart
これだけでは、さっぱりわからない。
LGBMのサイトのExperimentsに、xgboostとxgboost_histとLightGBMの性能を比較した結果があるが、その際に用いられているLGBMのパラメータは次のようになっている。
(・・・)は自分の付記である。
LightGBM:
learning_rate = 0.1(デフォルト)
num_leaves = 255(デフォルト:31)
num_trees = 500(num_iterationsと同じ?)
num_threads = 16(CPUのコア数)
min_data_in_leaf = 0(デフォルト:20)
min_sum_hessian_in_leaf = 100(デフォルト:1e-3)
12月24日(木)
- Riiid AIEd Challenge
- , 3,029 teams
- , 15 days to go
現在、0.782の最後尾:まだ2週間もあるので、このままでは、メダル圏外は確実だ:銀は0.785:金は0.805
LGBMのコードのfeatureの選択を行っている。
現状でほぼ最大値を示す状態から、各featureをOn, Offしたときのスコアの変化量を見ようとしている。各featureは独立しているとは限らないので、その扱いは単純ではないが、数値化することによって、先が見えてくるかもしれない。
各featureをOn, Offしたときのスコア変化を1つ1つ調べ、変化による差異を記録し、全てを調べた後で、プラス方向に変化するようにfeatureをon,offすれば、最適化が進むと考え、試してみた。
問題は、データ量と、収束条件をどうするかだ。
データ量はある程度の大きさで固定すれば良さそうである。
収束条件は、early_stoppingを使ったのだが、onとoffの差が小さく、有用なはずのfeatureがマイナスの評価になることがあった。こういう評価は、探索の前に、必ず、ばらつきを抑えておかないとだめだな。スコアがなかなか上がらないとあせってしまって、手抜きになって、十分な成果が得られない。不要なfeatureを選び、必要なfeatureを落としているかもしれない。
他にも問題がある。これもばらつきが原因なのだが、どうも、ドラフト計算結果よりcommit後の方が良くない結果になることが多い。これも、同一条件で3回繰り返せばはっきりするのだが、ドラフトとcommitで5~6時間以上かかっているので、同一条件の繰り返しは、できていない。何度かやろうとしたが、ついつい、パラメータをいじってしまう。同じ時間を費やすなら、異なるパラメータの結果を知りたいと思ってしまうのだが、結局、それも、ばらつきがわからないから、大小関係の判定が正しく行えないので意味不明の結果になってしまう。
今から、同一条件で、ドラフトーcommitを3回繰り返してみよう。ばらつきは、計算プロセスの中に存在し、ドラフトかcommitかは無関係なので、それぞれがばらついて、3回とも、commit後の値が小さくなる確率は非常に小さいはずだ。
1回目:ドラフト:0.7745、commit:0.7734
2回目:ドラフト:0.7742、commit:0.7743
3回目:ドラフト:0.7745、commit:0.7743
結果は、こうなった。いずれも、LGBM:500ラウンドの結果である。1回目のcommitが若干はずれている、というところか。
なぜ、commit後の値の方が小さくなると感じているのかを分析してみよう。
その答えは簡単である。
すなわち、計算は、何らかの指標によって改善が見込まれるときに行うので、途中経過が良くないと、中止してしまっているのである。反対に、途中経過が良いときには、気をよくしてcommit, submitに進むのである。つまり、途中経過が良くない場合に中止しないでcommitしていれば、ドラフトよりもcommit後の結果の方が良くなっていただろう、ということである。つまり、commit後の計算がいつも小さくなっているように感じるのは、途中経過が良い場合にのみ、commitしているからである。
予測モデルの汎用性を高めるには、計算を繰り返して、良い結果も悪い結果も全部含めて平均を取ることが効果的であって、良い結果だけの平均をとることは、汎用性を下げてしまうことになっている可能性が高い。いわゆるoverfittingである。
ヒトが介入することで、良くなることもあれば、悪くなることもある。
ということからすると、AとBのアンサンブルをする場合に、スコアの良い方の比重を上げようとすることが多いが、それは、overfittingにつながるかもしれない。public LBも常に向上するとは限らない。凝り固まらずに、いろいろ試してみることが重要。
どのコンペだったか、アンサンブルにアンサンブルを重ねて失敗したことがあった。private LBが最も良かったのは、全てのモデルの単純平均だったような気がする。このときは、ヒトが介入しすぎて、public_dataにoverfitしてしまったということだろうな。
そうだ、機械的にやればいい。・・学習ですから。
計算の合間に「ゼロからはじめるデータサイエンス」Joel Grus著、菊池彰訳
ソート
x = [ 4, 1, 2, 3 ]
y = sorted(x) # y = [ 1, 2, 3, 4 ]
x.sort( ) # x = [ 1, 2, 3, 4 ]
# 絶対値で降順にソート
x = sorted([ -4, 1, -2, 3], key=abs, reverse=True) # is [ -4, 3, -2, 1 ]
リストの連結
x = [1, 2, 3]
x.extend([4, 5, 6]) # リストxは、[1, 2, 3, 4, 5, 6]になる。
要素の追加
x = [1, 2, 3]
x.append(0) # リストxは、[1, 2, 3, 0]となった。
z = len(x) # z = 4
12月25日(金)
Riiid AIEd Challenge, 3,061 teams, 14 days to go
昨日はmax_round=500で実施したが、earlystopの条件を満たさず、3回ともmax_roundの500で停止した。
次は、max_round=1000、にして、3回繰り返してみる。
ちょっと(5時間程度)やってみたが、昨日の3回の結果でLBスコアの改善が見られなかったことと、繰り返し再現性(ばらつき)についてある程度の知見は得られたので、スコアアップのための他の方法を検討する。
featureを順位の高い方から10件だけ使うとか、30件くらい使うとか、いろいろやっているが、val_AUCが上がらない。下がることの方が多い。
正直、途方に暮れている。
こういうときに、最も簡単で効果的な方法がある。
これまで最高のスコアを出したコードに戻って、そこから、確実な改善を積み重ねることである。ここから、まだ、ハイスコアのコードが公開される可能性は高いが、だからといって、まだ、そういうものと戦う力は無いので、一足飛びに上を目指すのは少し横においておこう。
まずは、0.782の中を這い上がろう。
計算の合間に「ゼロからはじめるデータサイエンス」Joel Grus著、菊池彰訳
リスト内包
even_numbers = [x for x in range(5) if x % 2 == 0] # [0, 2, 4]
squares = [x * x for x in range(5)] # [0, 1, 4, 9, 16]
even_squares = [x * x for x in even_numbers] # [0, 4, 16]
square_dict = { x : x * x for x in range(5)} # { 0:0, 1:1, 2:4, 3:9, 4:16 }
square_set = { x * x for x in [1, -1]} # { 1 }
簡単な表現で十分に慣れておけば、実際の場面でも理解できるようになるだろう。
アンダースコア "_" も慣れておけば、出くわしたときに、あわてなくてすむ。
zeros = [ 0 for _ in even_numbers ] # even_numbersと同じ長さの0が続くリスト
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve J ´ egou ´, Facebook AI, Sorbonne University
Abstract
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification.
However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, thereby limiting their adoption by the larger community.
In this work, with an adequate training scheme, we produce a competitive convolution-free transformer by training on Imagenet only.
We train it on a single computer in less than 3 days. Our reference vision transformer
(86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external data. We share our code and models to accelerate community advances on this line of research.
Additionally, we introduce a teacher-student strategy specific to transformers.
It relies on a distillation token ensuring that the student learns from the teacher through attention.
We show the interest of this tokenbased distillation, especially when using a convnet as a teacher.
This leads us to report results competitive with convnets for both Imagenet (where
we obtain up to 84.4% accuracy) and when transferring to other tasks.
12月26日(土)
Riiid AIEd Challenge, 3,098 teams, 13 days to go
残り2週間を切った。0.8+に至る道は、まだ見えない。
0.79+レベルのコメントでは、公開コードにあるfeatureの組み合わせでは不十分で、さらに工夫が必要になるとのこと。
***雑談***
Python系のプログラミング技術の習得が不十分であるために自分でプログラムを組むことができないからフォークするのか、それとも、課題を解決する方法がわからないためにプログラミングするところまでいかないからフォークするのか。
優れたプログラミング技術と優れた課題解決方法を学ぶためにフォークしているのです、と答えたいところだが、実際のところは、リーダーボードに掲載されてみたいし、あわよくばメダルを獲得したいからである、ということになろうか。
フォークすること自体は何の問題もない。問題があるとすれば、フォークしたコードをそのまま実行し、その結果をsubmitしてしまうことである。いや、これも問題はない。フォークしたコードをチューニングすることも加工することも、問題はない。
公開コードは、ある程度の時間が経てば、初級レベルからメダル圏内に入りそうなレベルのものまで公開されている。したがって、十分な時間があれば、手作りから始めて、わからないところは、公開コードを参考にしながら、プログラムを組み上げていけばよいのである。この作業を丁寧にやっていれば、プログラミング技術は向上し、課題解決能力も向上していく。
12月27日(日)
Riiid AIEd Challenge, 3,122 teams,12 days to go
0.783の爆弾が落とされて、メダル圏外に放り出されてしまった。
このコードは、0.780、0.781と似ているが、LGBMモデルに学習させるfeatureの数と種類が異なっていて、データ量も違っている。
データ量とfeature数は逆相関になっていて、データ量を増やすには、featureを減らす必要があった。公開コードの0.780と0.781が示していた(暗示していた)ことは、feature数を減らしてデータ量を増やせば、0.001だけLBが上がるということであった。
200チーム以上がフォークしてチューニングを試みたと思うが、この方向が効果的であれば、0.782になだれ込むはずだが、そうはならなかった。自分も、featureを減らしてデータ量を増やすことでLBアップを狙ったが、労力の割には効果は小さかったと思う。
0.781の中を通って、0.782の仲間入りを果たしたまでは良かったが、0.782の最後尾に張り付いたまま動けなくなった。
現在、0.783のコードが 2つ公開されているが、まさにこのfeature数とデータ量の違いである。feature量を効果的に減らしてデータ量を増やすか、データ量は押さえてfeatureの種類を増やすかの2者択一になっている。
では、もっと上位の方々は、どういう方法を用いてるのだろうか。
アンサンブルかな。
SAKT、SAINT、TabNet、1次元CNNやLSTM、GRUなどの従来型のRNNなど様々な手法のモデルのアンサンブルが有効なのかもしれない。
公開コードの中に存在しているものを適切に組み合わせる技術があればいいのだが。
今後のためにも、その方法を少しでも多く学んでおこう。
12月28日(月)
Riiid AIEd Challenge, 3,161 teams, 11 days to go
銀以上を狙っているのだが、現状では、銅も難しい。
競争が本格化するのはここからだ。1週間前、3日前と、さらに厳しくなる。
0.783をフォークしてチューニングしているが、前進できない。featureの選び方に不自然さを感じたので、これまで自分なりに順位付けしていたfeatureを優先的に選んでみたが、val_aucは上がっても、LBスコアは上がらない。
不思議なのは、40個以上あるfeatureのうちで、feature importanceが小さい5つを除いてみると、val_aucは0.0013上がるが、LBは上がらない。それだけでなく、feature importanceの順番と分布が一目でわかるくらい大きく変わったことである。
ということから、val_aucの値とfeature importanceの分布が、それぞれ適切な値/分布になるときに、LBスコアは上がるということのようなので、探索範囲を拡げて1つ1つ調べていく必要がありそうだ。
計算の合間に文法を学ぼう。
.replace:文字列を置換する
pandas.get_dummies():
note.nkmk.meから引用:
pandasでカテゴリ変数(カテゴリカルデータ、質的データ)をダミー変数に変換するには、pandas.get_dummies()関数を使う。
文字列でカテゴリー分けされた性別などのデータを、男を0, 女を1のように変換したり、多クラスの特徴量をone-hot表現に変換したりすることができる。機械学習の前処理として行うことが多い。
例として以下のデータを使用する。説明のために列を追加している。
import pandas as pd
import numpy as np
df = pd.read_csv('data/src/sample_pandas_normal.csv', index_col=0)
df['sex'] = ['female', np.nan, 'male', 'male', 'female', 'male']
df['rank'] = [2, 1, 1, 0, 2, 0]
print(df)
# age state point sex rank
# name
# Alice 24 NY 64 female 2
# Bob 42 CA 92 NaN 1
# Charlie 18 CA 70 male 1
# Dave 68 TX 70 male 0
# Ellen 24 CA 88 female 2
# Frank 30 NY 57 male 0引数にpandas.DataFrameを指定する場合
pandas.DataFrameの場合は、デフォルトではデータ型dtypeがobject(おもに文字列)またはcategoryである列がすべてダミー変数化される。
数値(int, float)やブールboolの列は変換されず元のまま。数値やブールの列もダミー化したい場合の設定については後述。
pandas.DataFrameの場合の列名は元の列名_カテゴリー名となる。変更する設定は後述。
print(pd.get_dummies(df))
# age point rank state_CA state_NY state_TX sex_female sex_male
# name
# Alice 24 64 2 0 1 0 1 0
# Bob 42 92 1 1 0 0 0 0
# Charlie 18 70 1 1 0 0 0 1
# Dave 68 70 0 0 0 1 0 1
# Ellen 24 88 2 1 0 0 1 0
# Frank 30 57 0 0 1 0 0 1
これ以上の転載はやめておく。
pd.get_dummies( )を使いこなせるようになろう。
.groupby:note.nkmk.meから引用
pandas.DataFrameをGroupByでグルーピングし統計量を算出
pandas.DataFrame, pandas.Seriesのgroupby()メソッドでデータをグルーピング(グループ分け)できる。グループごとにデータを集約して、それぞれの平均、最小値、最大値、合計などの統計量を算出したり、任意の関数で処理したりすることが可能。
なお、マルチインデックスを設定することでも同様の処理ができる。以下の記事を参照。
関連記事: pandasのMultiindexで階層ごとの統計量・サンプル数を算出
また、pandas.pivot_table(), pandas.crosstab()という関数を用いてカテゴリごとの統計量やサンプル数を算出することもできる。この方法が一番シンプルかも知れない。
関連記事: pandasのピボットテーブルでカテゴリ毎の統計量などを算出
関連記事: pandasのcrosstabでクロス集計(カテゴリ毎の出現回数・頻度を算出)
groupby()でグルーピング
pandas.DataFrameのgroupby()メソッドでグルーピング(グループ分け)する。なお、pandas.Seriesにも同様にgroupby()メソッドがある。
pandas.DataFrame.groupby — pandas 1.0.4 documentation
pandas.Series.groupby — pandas 1.0.4 documentation
引数に列名を指定するとその列の値ごとにグルーピングされる。
GroupByオブジェクトからメソッドを実行することでグループごとに処理ができる。メソッド一覧は以下の公式ドキュメント参照。
GroupBy — pandas 1.0.4 documentation
例えばsize()メソッドでそれぞれのグループごとのサンプル数が確認できる。
平均、最小値、最大値、合計などを算出
上記のメソッド一覧にあるように、GroupByオブジェクトに対しmean(), min(), max(), sum()などのメソッドを適用すると、グループごとの平均、最小値、最大値、合計などの統計量を算出できる。
そのほか標準偏差std()、分散var()などもある。
いずれのメソッドも新たなpandas.DataFrameを返す。
任意の処理を適用して集約: agg()
GroupByオブジェクトのagg()メソッドで任意の処理を適用することもできる。
pandas.core.groupby.GroupBy.agg — pandas 1.0.4 documentation
引数に適用したい処理を指定する。
GroupByオブジェクトのメソッド名を文字列で指定できるほか、組み込み関数やNumPyの関数などの呼び出し可能オブジェクト(callable)を指定可能。
関連記事: pandasのagg(), aggregate()の使い方
.reset_index:
pandas.DataFrame, Seriesのインデックスを振り直すreset_index
reset_index()メソッドを使うと、pandas.DataFrame, pandas.Seriesのインデックスindex(行名、行ラベル)を0始まりの連番(行番号)に振り直すことができる。
pandas.DataFrame.reset_index — pandas 0.22.0 documentation
行番号をインデックスとして使っている場合、ソートして行の順番が変わったときや行を削除して欠番が出たときなどはインデックスを振り直したほうが使いやすい。
また、行名(行ラベル)をインデックスとして使っている場合に、現在のインデックスを削除したりデータ列に戻すためにも使う。set_index()とreset_index()を使うことで、インデックスを別の列に変更(再設定)することができる。
feature enginering:
An Empirical Analysis of Feature Engineering for Predictive Modeling
Jeff Heaton, SoutheastCon 2016, 2016 - ieeexplore.ieee.org
I. INTRODUCTION
Feature engineering is an essential but labor-intensive component of machine learning applications [1]. Most machinelearning performance is heavily dependent on the representation of the feature vector. As a result, data scientists spend much of their effort designing preprocessing pipelines and data transformations [1]. To utilize feature engineering, the model must preprocess its input data by adding new features based on the other features [2]. These new features might be ratios, differences, or other mathematical transformations of existing features. This process is similar to the equations that human analysts design. They construct new features such as body mass index
(BMI), wind chill, or Triglyceride/HDL cholesterol ratio to help understand existing features’ interactions. Kaggle and ACM’s KDD Cup have seen feature engineering play an essential part in several winning submissions. Individuals applied feature engineering to the winning KDD Cup 2010 competition entry [3]. Additionally, researchers won
the Kaggle Algorithmic Trading Challenge with an ensemble of models and feature engineering. These individuals created these engineered features by hand.
... the following sixteen selected engineered features:
• Counts
• Differences
• Distance Between Quadratic Roots
• Distance Formula
• Logarithms
• Max of Inputs
• Polynomials
• Power Ratio (such as BMI)
• Powers
• Ratio of a Product
• Rational Differences
• Rational Polynomials
• Ratios
• Root Distance
• Root of a Ratio (such as Standard Deviation)
• Square Roots
こういう演算によってfeatureを作り出すということのようだ。
LGBMを使った公開コードを見ていると、これらの演算を使ってfeatureを作っていることがわかる。演算の種類も、featureの組み合わせ方も重要で、いかにして良いfeatureを作り出すか、ということなんだろうな。
12月29日(火)
Riiid AIEd Challenge, 3,184 teams, 10 days to go
昨夜、LGBMのパラメータ:feature_fractionが気になって、値を少し大きく変えて計算してみた。そうすると、feature_importanceの分布がその値によって大きく変わることがわかった。val_aucの値も変化している。submitしてLBスコアを確かめよう。LBスコアは少し改善した。といっても、0.001以下でのこと。
計算の合間にLGBMとfeature_engineering:
Francois Chollet “Developing good models requires iterating many times on your initial ideas, up until the deadline; you can always improve your models further. Your final models will typically share little in common with the solutions you envisioned when first approaching the problem, because a-priori plans basically never survive confrontation with experimental reality.”
Francois Chollet「優れたモデルを開発するには、締め切りまで、最初のアイデアを何度も繰り返す必要があります。 モデルはいつでもさらに改善できます。 事前の計画は基本的に実験的な現実との対立に耐えることができないため、最終的なモデルは通常、最初に問題に取り組むときに想定したソリューションとほとんど共通点がありません。」
by google translation
12月30日(水)
Riiid AIEd Challenge, 3,211 teams, 9 days to go
意味を理解できていないパラメータを意味の分からない値に設定しながら、ようやく0.785に到達した。
今朝、自信をもってsubmitしたが、前進できなかった。改善は、ばらつきの範囲で、偶然生じただけかもしれない。
確認のためには、同一条件での計算を、3回繰り返すことになる。
ばらつきによって上がったのを、パラメータが適切であったと思ってしまったら、誤った方向に行くことになる。
さらに、忘れてはならないのは、private_dataへのover-fittingである。
「意味を理解できていないパラメータを意味の分からない値に設定しながら」:こういうことだと、public_LBだけを頼りにfeatureの選択やパラメータの設定をすることになるので、public_dataへのoverfittingになりやすい。
チューニングが行き詰ってきたこともあり、LightGBMのマニュアルの ”Parameters Tuning"を参考に、num_leavesとmin_data_in_leafとmax_depthを用いて、条件検討をやりなおすことにした。num_leavesしか使っていなかったので、他の2つは適当に値を設定してやってみたら、10時間くらいで、なんとなくそれらしい結果が出始めた。そこで、submitではなく、記録のためにcommitしたら、commitの途中で、"[Worning] No further splits with positive gain, best gain: -inf"というメッセージが現れた。これはダメだろうと思い、中断して、調べたら、min_data_in_leafの設定値、1024が大きすぎることによるものであるらしい、ということがわかった。
マニュアルには、大きなデータの場合には数百もしくは数千で十分"In practice, setting it to hundreds or thousands is enough for a large dataset".とあったので、間をとって1024にしたのだが、この1024が不適切だったようだ。
そこで、min_data_in_leafを512, 256, 128とかえてみたが、同じ症状だった。ドラフト計算可能、良好な結果が得られている。しかし、commitすると、警告が出る。
min_data_in_leafは、over-fittingしないための非常に重要なパラメータである(This is a very important parameter to prevent over-fitting in a leaf-wise tree.、と書かれている。
なんとかして、使いこなしたいものだ。
計算の合間にLGBMとfeature_engineering:
bagging_fractionの使い方:指定した割合のデータをランダムにサンプリングする。
pos_とneg_があって、used for imbalanced binary classification problem、となっている。今回のRiiidコンペの場合だと、正答率が約65%でアンバランスだから、正答をpositiveとすれば、pos_bagging_gractionを0.35、neg_bagging_fractionを0.65とすれば、サンプリングしたデータ中には、正答と誤答が同等の割合で含まれることになる。ただし、他の方法で補正しているかもしれないので、公開コードを使うときには、全部調べてからにしないと、これを使ったがために、かえって、アンバランスを生じる可能性がある。しかしながら、理屈通りに動作するとは限らないので、比率を系統的に変えてみて、結果がどうなるかを実験してみるのも、よいかもしれない。
feature_fractionもbagging_fractionも、”can be used to speed up training、can be used to deal with over-fitting””という記述がある。直観的には、dropoutに似た効果かなと思う。
LGBMのParameterの説明について"over-fitting"を検索すると、次のパラメータが、over-fittingに関連していることがわかる。
"extra_trees", "max_bin", "min_data_in_bin", "max_depth", "min_data_in_leaf", "min_sum_hessian_leaf",
"max_bin"は、"small number of bins may reduce training accuracy but may increase general power (deal with over-fitting)"、と記述されている。
max_binは、accuracyが上がることを期待して大きな値にセッティングしがちだが、generalizationとのバランスが必要のようだ。
LightGBMのマニュアルの”Parameters Tuning"をじっくり眺めてみよう。
Tune Parameters for the Leaf-wise (Best-first) Tree
LightGBM uses the leaf-wise tree growth algorithm, while many other popular tools use depth-wise tree growth. Compared with depth-wise growth, the leaf-wise algorithm can converge much faster. However, the leaf-wise growth may be over-fitting if not used with the appropriate parameters.
To get good results using a leaf-wise tree, these are some important parameters:
-
num_leaves. This is the main parameter to control the complexity of the tree model. Theoretically, we can setnum_leaves = 2^(max_depth)to obtain the same number of leaves as depth-wise tree. However, this simple conversion is not good in practice. The reason is that a leaf-wise tree is typically much deeper than a depth-wise tree for a fixed number of leaves. Unconstrained depth can induce over-fitting. Thus, when trying to tune thenum_leaves, we should let it be smaller than2^(max_depth). For example, when themax_depth=7the depth-wise tree can get good accuracy, but settingnum_leavesto127may cause over-fitting, and setting it to70or80may get better accuracy than depth-wise. -
min_data_in_leaf. This is a very important parameter to prevent over-fitting in a leaf-wise tree. Its optimal value depends on the number of training samples andnum_leaves. Setting it to a large value can avoid growing too deep a tree, but may cause under-fitting. In practice, setting it to hundreds or thousands is enough for a large dataset. -
max_depth. You also can usemax_depthto limit the tree depth explicitly.
リーフワイズ(ベストファースト)ツリーのパラメーターを調整する
LightGBMは葉ごとのツリー成長アルゴリズムを使用しますが、他の多くの一般的なツールは深さ方向のツリー成長を使用します。深さ方向の成長と比較して、葉方向のアルゴリズムははるかに速く収束できます。ただし、適切なパラメーターを使用しないと、葉ごとの成長が過剰適合する可能性があります。
リーフワイズツリーを使用して良好な結果を得るには、次のいくつかの重要なパラメーターがあります。
num_leaves:これは、ツリーモデルの複雑さを制御するための主要なパラメーターです。理論的には、num_leaves = 2 ^(max_depth)を設定して、深さ方向のツリーと同じ数の葉を取得できます。ただし、この単純な変換は実際には適切ではありません。その理由は、葉の数が決まっている場合、通常、葉の数のツリーは深さのツリーよりもはるかに深いためです。制約のない深さは、過剰適合を引き起こす可能性があります。したがって、num_leavesを調整しようとするときは、2 ^(max_depth)より小さくする必要があります。たとえば、max_depth = 7の場合、深さ方向のツリーは良好な精度を得ることができますが、num_leavesを127に設定すると過剰適合が発生する可能性があり、70または80に設定すると深さ方向よりも精度が高くなる可能性があります。
min_data_in_leaf:これは、葉ごとのツリーでの過剰適合を防ぐための非常に重要なパラメーターです。その最適値は、トレーニングサンプルとnum_leavesの数によって異なります。大きな値に設定すると、ツリーが深くなりすぎるのを防ぐことができますが、フィットが不十分になる可能性があります。実際には、大規模なデータセットの場合は、数百または数千に設定するだけで十分です。
max_depth: max_depthを使用して、ツリーの深さを明示的に制限することもできます。 by google translation
この文章は、LGBMはパラメータを適切に設定しないで使うとover-fittingします、という忠告文としてとらえるのがよさそうである。
12月31日(木)
Riiid AIEd Challenge, 3,234 teams, 8 days to go
min_data_in_leafとmax_depthは、over-fittingの抑制に効果的だということは実感できたが、commit中にエラーになるのでは使えない。
この2つが競合していると仮定して、片方だけ使うことにしてみる。min_data_in_leafの方が重要だとの記述から、最初に、max_depthを省いてみる。それでだめなら、逆にする、それでもだめなら、今回は両方とも使わないことにする。
max_depthを省くことで、commit中のエラーは表示されなくなった。
ただし、max_depthが、over-fittingの抑制にかなり寄与していたことがわかったので、min_data_in_leafをさらに調整する必要がある。


