Application of Machine Learning in Optimizing Proton Exchange Membrane Fuel Cells: A Review
Rui Ding et al., Energy and AI 9 (2022) 100170
A B S T R A C T
Proton exchange membrane fuel cells (PEMFCs) as energy conversion devices for hydrogen energy are crucial for achieving an eco-friendly society, but their cost and performance are still not satisfactory for large-scale commercialization. Multiple physical and chemical coupling processes occur simultaneously at different scales in PEMFCs. Hence, previous studies only focused on the optimization of different components in such a complex system separately. In addition, the traditional trial-and-error method is very inefficient for achieving the performance breakthrough goal. Machine learning (ML) is a tool from the data science field. Trained based on datasets built from experimental records or theoretical simulation models, ML models can mine patterns that are difficult to draw intuitively. ML models can greatly reduce the cost of experimental attempts by predicting the target output. Serving as surrogate models, the ML approach could also greatly reduce the computational cost of numerical simulations such as first-principle or multiphysics simulations. Related reports are currently trending, and ML has been proven able to speed up tasks in this field, such as predicting active electrocatalysts, optimizing membrane electrode assembly (MEA), designing efficient flow channels, and providing stack operation strategies. Therefore, this paper reviews the applications and contributions of ML aiming at optimizing PEMFC performance regarding its potential to bring a research paradigm revolution. In addition to introducing and summarizing information for newcomers who are interested in this emerging cross-cutting field, we also look forward to and propose several directions for future development.
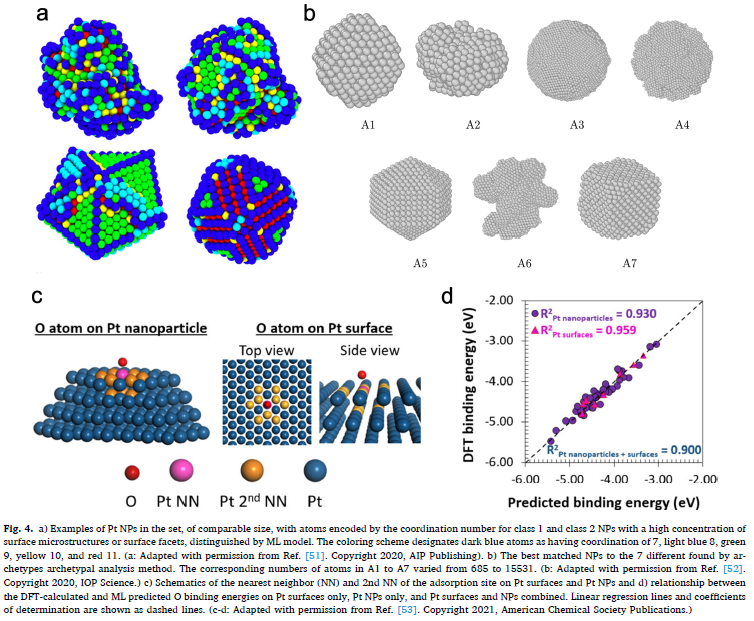
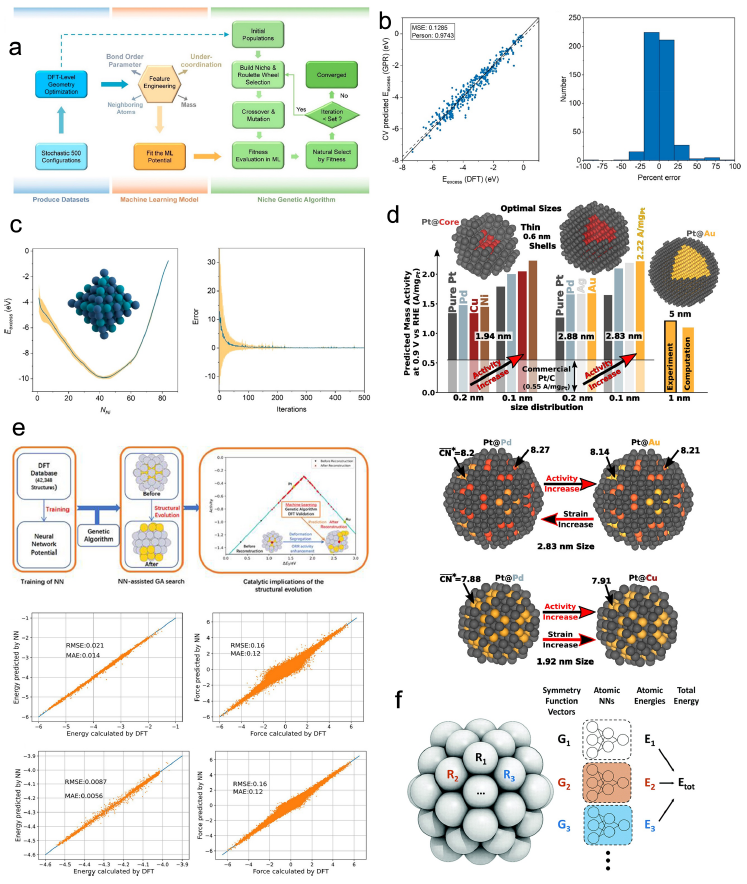
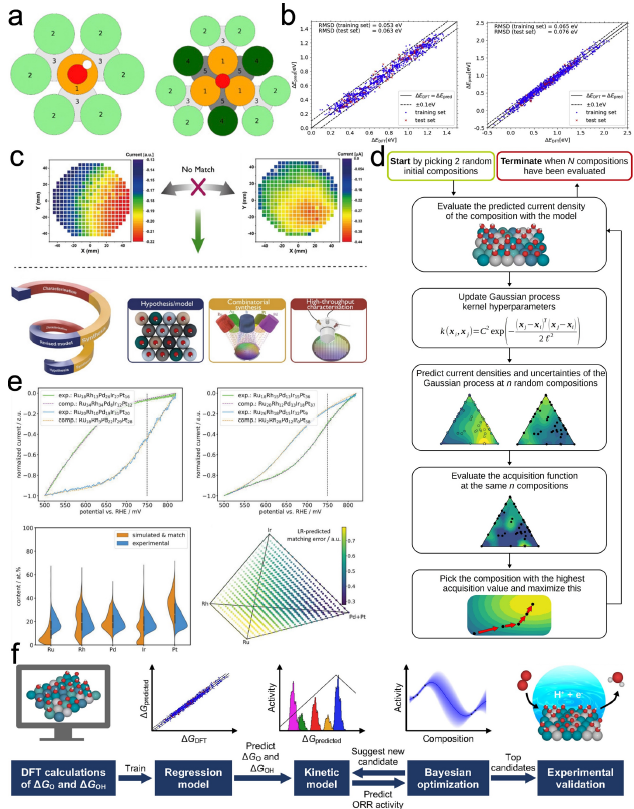
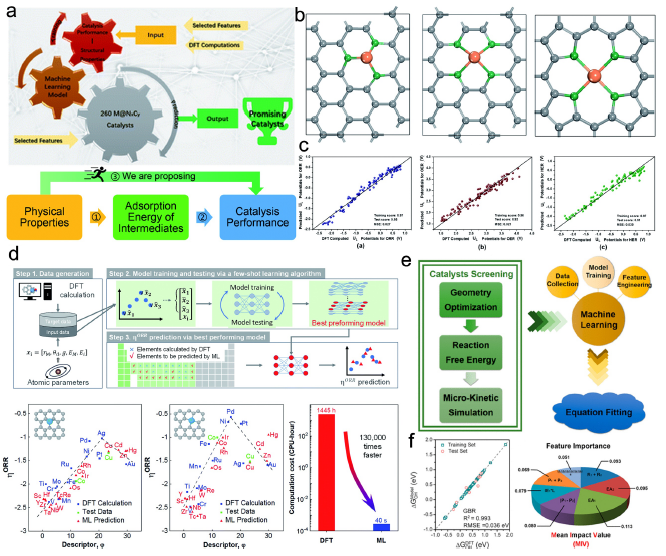

図面を並べてみただけだが、燃料電池をトータルで理解するにはどれだけのことを知らなければならないのか・・・。
5. Conclusion and Outlooks
As a complex energy conversion device, achieving multiparameter optimization of a PEMFC is a difficult process. Using traditional trial and error methods is inefficient, while ML methods allow it to be handled as a black box. The construction of data-driven models based on experimental data enables the mapping of experimental/operational
parameters of interest or certain observations directly to the desired target output. In addition, ML can be trained based on numerical simulation models such as DFT and CFD, which, as surrogate models, greatly reduce the computational cost of finding optimal parameters, leading to better power density. Both ideas are currently used in the most reports in the field of PEMFC to achieve higher performance in related materials and components. From microscopic to macroscopic scales, such as nanoelectrocatalysts, CL, GDL, PEM, MEA, flow fields, single cells, and stacks, the application is wide and successful. However, we still need to point out the current existing limiting problems and the future direction of the field.
1 Current ML applications are dominated by supervised learning, which has led to the need for researchers to prepare large sets of annotated data to train ML models. Whether this comes from highthroughput experiments or computationally expensive numerical simulations, the costs are relatively high. There are several ideas of ways to address this problem. The first is the development of an efficient experimental device for
conducting automatic experiments; Cooper et al. developed robotic chemists with humanoid features that can work on their own in a standard laboratory using various experimental apparatuses, such as humans [156]. By combining this with Bayesian optimization, the idea is similar to that of guiding experiments through ML models and
making additions to the dataset to form a complete R&D cycle, as mentioned previously in Ref. [88]. The 1.75-meter-tall AI robot completed 668 experiments independently in eight days and developed a completely new chemical catalyst. However, similar robots
may still cost more than employing experimenters. However, as computer vision develops and reports in related fields continue to be launched, the technology for fully automated experimental robots will become more realistic. The second is the development and application of the few shot learning algorithms [157] to accommodate low-cost, small volume datasets. However, the current research is mainly focused on the
field of computer vision. Beyond this, there are two similar general approaches. The first is transfer learning [158], where the knowledge or patterns learned on one domain or task are applied to a different but related domain or problem using models that have
already been trained and adapted. The second is data augmentation [159], a technique that is also primarily used in image recognition. By rotating, adding noise, and cropping the images in the training set, it is possible to increase the size of the training set and improve the effectiveness of the ML model. This idea is also worthwhile. The third is the flexible use of unsupervised learning and other methods that do not require annotated data. Clustering in Ref. [160], for example, can be used to find commonalities in the experimental parameters among data records that have the desired performance, and thus, high-value information can be obtained. In addition, the use of the Apriori associate rule mining methods [161] that have been reported to reveal frequent item sets is also very effective for performing similar tasks without model training.
2 ML models, as they are data-driven models, are still black-box models. Despite the ability to make effective and accurate predictions when training data are available, researchers still need to gain a deeper understanding of how ML models determine output performance based on input variables with specific meanings in physical or chemical processes. The introduction of ML interpretation tools can help to improve the credibility of ML models and, on the other hand, help us uncover important information that is latent in more complex systems such as PEMFC systems. On the other hand, researchers will also be able to compare ML insights with scientific domain knowledge, thus correcting potential biases due to the dataset. This will be a collaborative effort between ML models and researchers.
3 The construction of ML models is currently still only possible in known parameter spaces. Therefore, despite being called AI, ML models cannot introduce innovations (new parameters, methods, or variables that have never existed before) to a material system from scratch in the same way that a real researcher can. Therefore, ML still needs to be combined with human researchers. ML models can serve as an aid to help us to get from 1 to 100, but the real 0 to 1 can still only be achieved by a talented human. To make breakthroughs, advances in artificial general intelligence (AGI) should be considered.
At the current stage, possible progress might be achieved by developing meta learning, namely, learning to learn [162]. The goal is to enable the model to acquire an ability to learn to tune hyperparameters so that it can quickly learn new tasks based on the acquired knowledge. When there are many ML cases available for learning in the same domain (e.g., PEMFC), these ML cases can be used as materials for training meta-learning models. Ultimately, meta-learning models may be similar to human researchers, with a
certain ability to mine unknown directions of inquiry.
4 In addition to the aforementioned expansion and improvement from ML methods and applications, from the PEMFC’s perspective, there are also some directions that can be developed in the future for better mutual benefit with ML. The first is that for the development of PEMFC materials, the synthesis preparation and experimental operation description should be standardized. A third-party standard testing organization (similar to solar cells) should be established to improve the reliability of the PEMFC performance test data. This will improve the quality of the database to facilitate ML modeling. The second point is to promote in-depth cooperation between academia and industry on the basis of the former, build a big data sharing platform, and actively open up data availability for researchers in the field.
5 Finally, the main bottleneck restricting the large-scale application of PEMFCs is still the Pt capacity. To achieve this goal of overcoming this bottleneck, the development of catalysts with higher catalytic activity and lower cost and the optimization of membrane electrode processes are the directions that the academic community should continue to pay attention to. At present, high-entropy alloy electrocatalysts [59, 163, 164] and gradient MEAs [165, 166] may be the main research systems in the next stage. However, there are still no reports on the application of ML to the optimization of related systems.
Therefore, promoting research in these frontier directions is recommended.
